Your mine generates terabytes. Your AI models can use almost none of it.
Mining operations produce enormous volumes of data. Most of it cannot be used for AI. Understand what enterprise AI data readiness actually requires in a mining context.

6
min read

Terabytes underground. Untapped intelligence above ground.
Data volume is not data readiness. Here is what AI-ready mining data actually looks like, and why getting there is Stage 01 of productionising enterprise AI.
A modern mine generates data at a scale most industries cannot match. Sensors on haul trucks, vibration readings from SAG mills, process historians logging tens of thousands of SCADA tags per second, maintenance work orders in the ERP, ore grade measurements from the laboratory, safety and environmental reports filed daily. The data exists. It is abundant. And for most mining operations running AI initiatives, very little of it can actually be used to build and sustain production AI models.
This is the defining challenge of enterprise AI data readiness in mining. Not a shortage of data. A shortage of data that is clean, connected, contextualised, governed, and structured in a way that machine learning pipelines can work with.
The question is not how much data your mine produces. The question is how much of it an AI model can actually learn from.
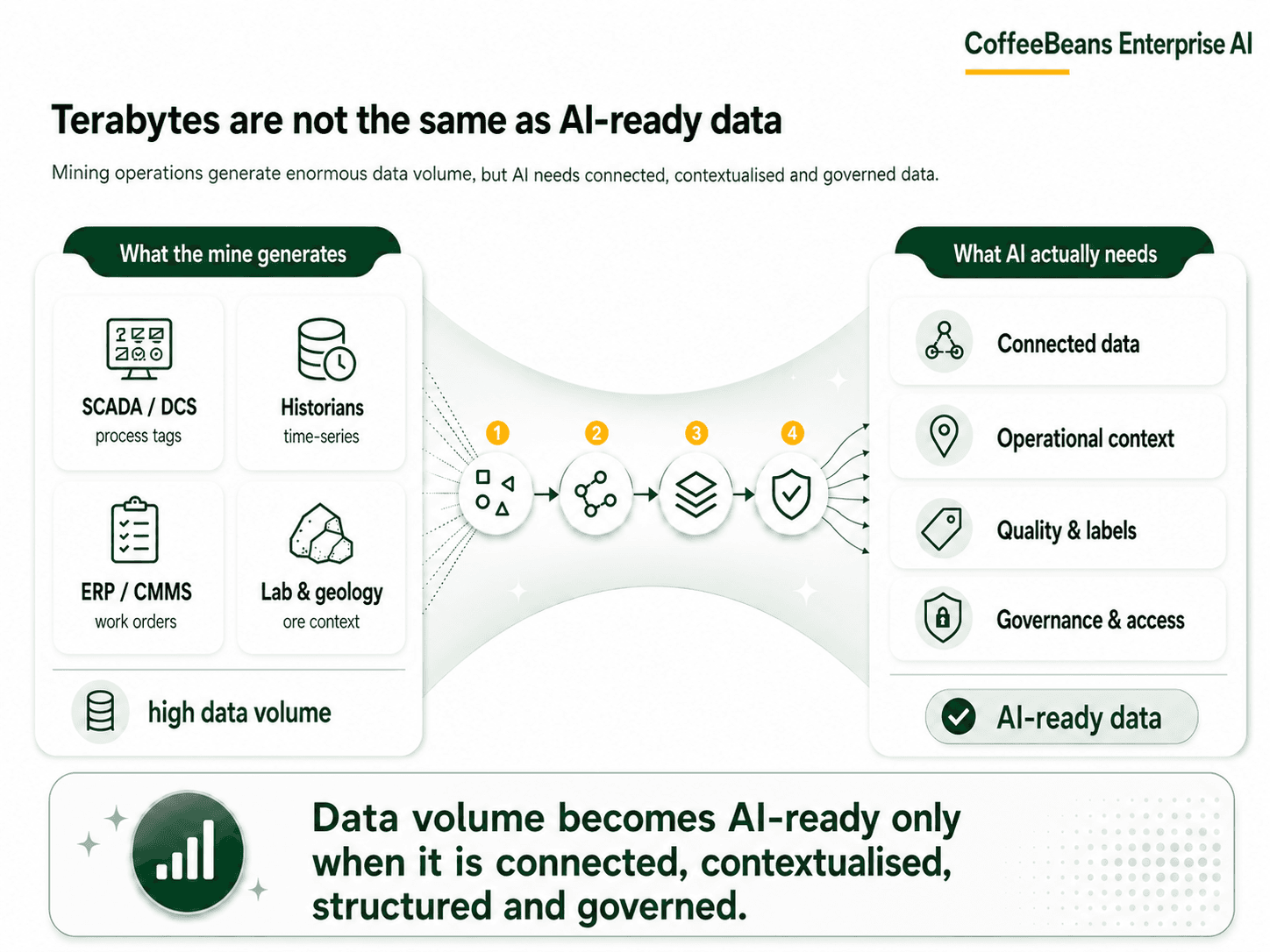
Mining has more data than ever. Most of it is not AI-ready.
Across the operations we have worked in, the pattern is consistent. The data infrastructure exists. There are historians. There are SCADA systems. There are fleet management platforms, asset management systems, and ERP layers. The problem is not that data is absent. The problem is that it was built for operations, not for machine learning.
Process historians, for example, are designed to store time-series readings from physical instruments. They do an excellent job of that. What they do not do is catalogue those readings, associate them with equipment context, link them to maintenance events, or make them accessible to ML pipelines without significant transformation work. A historian tag reading 3,412 RPM means very little to a model that does not know what equipment generated it, what ore type was being processed, what the load was, or whether a maintenance intervention had happened two days earlier.
The same applies across the data landscape of a typical mine. Maintenance logs exist in text fields that were written for technicians, not for training datasets. Geological models are stored in specialised formats that were never designed to interface with a data lakehouse. Fleet telemetry is captured by vendor platforms that sit outside the plant network. Environmental monitoring data is filed for compliance purposes and rarely connected to operational context. Each of these systems holds genuinely valuable information. Very little of it is connected, and almost none of it is in a form that a model can immediately use.
Where mining data gets trapped
The fragmentation problem in mining is structural. Most mining operations have grown their data infrastructure over decades, layering new systems on top of older ones without ever building a unified data architecture. The result is a landscape that looks like this:
OT systems (SCADA, DCS, historians) that are isolated from IT systems by air gaps, network boundaries, or vendor restrictions
Multiple historians running in parallel, often from different vendors, with inconsistent tag naming conventions and no shared metadata schema
Maintenance data in the ERP that exists as free-text notes rather than structured, searchable records
Geological and orebody data stored in proprietary formats that predate modern data engineering tooling
Fleet telemetry captured by OEM platforms with limited API access and no standard data contract
Safety and ESG data filed in compliance systems with no connection to operational data
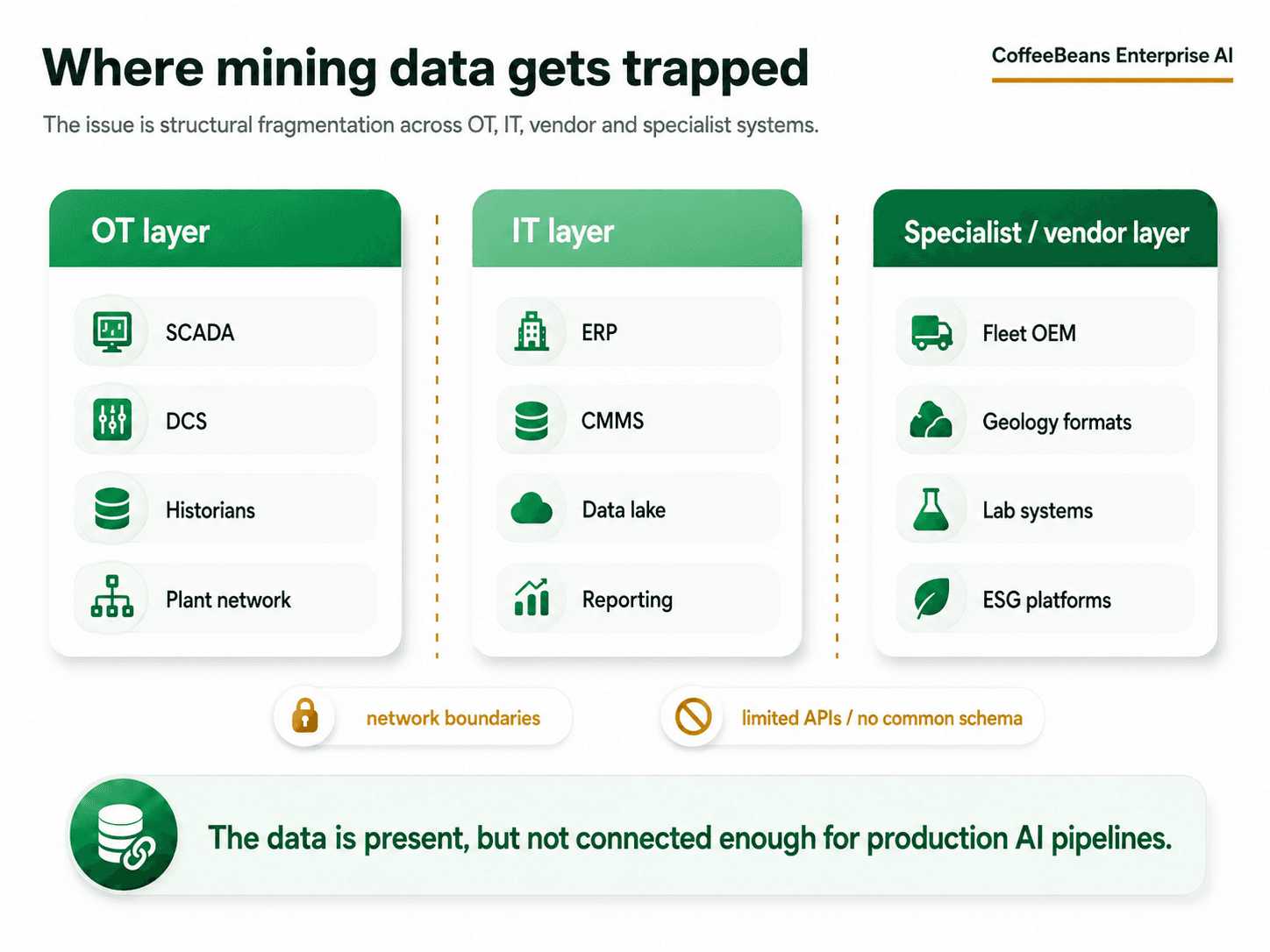
The result is not a data shortage. It is a data fragmentation problem that is almost invisible until someone tries to train a model on it.
McKinsey's research on AI scaling in manufacturing confirms this pattern across industrial sectors: the organisations that achieve meaningful returns from AI are those that invest in IT/OT data integration and unified data workflows before selecting modelling techniques. Those that attempt to build models first and fix the data later consistently find themselves unable to move from pilot to production. (Source: McKinsey, 'From pilots to performance: How COOs can scale AI in manufacturing,' 2025.)
Why AI models cannot learn from raw operational data
This is the point that most AI conversations in mining miss. A model does not learn from data. It learns from structured, labelled, contextualised, and governed representations of data that have been processed into features it can actually work with.
A raw vibration reading from a SAG mill bearing is not a feature. It becomes a feature when it has been associated with the specific mill, aligned with the operating load at that moment, connected to the maintenance history of that bearing, labelled against known failure events, and made available through a pipeline that produces the same result in production as it did during training.
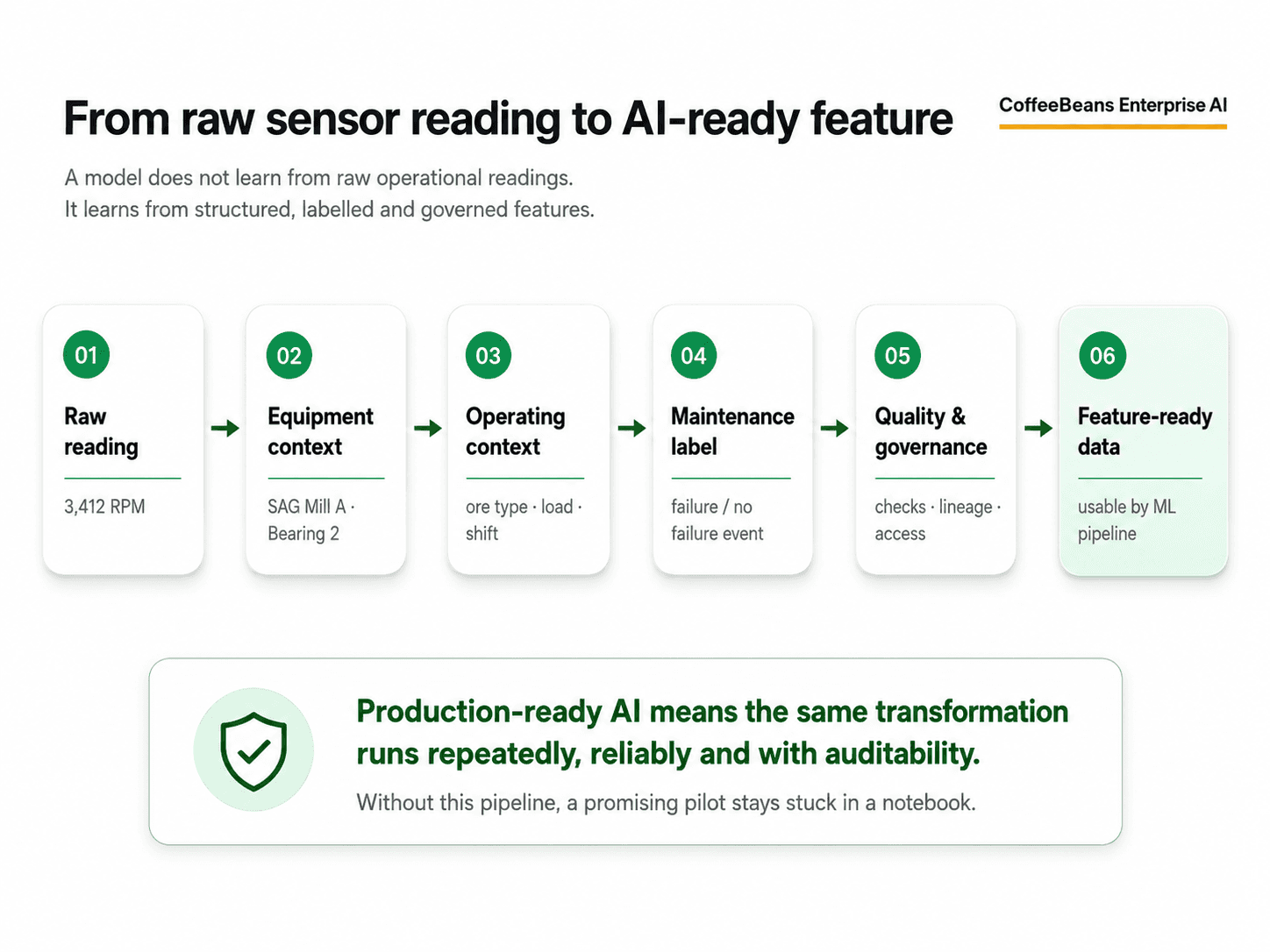
That transformation work is not trivial. In our experience working with mining and industrial clients, it is the stage that takes the longest and is most frequently underestimated. Teams assume that because the data exists, the hard part is over. The hard part is usually just beginning.
In a recent engagement with a large mining operation running heavy equipment fleets across challenging terrain, CoffeeBeans encountered exactly this problem at scale. Each piece of equipment was generating thousands of sensor parameters per second. The data volume was not the challenge. The challenge was that sensor streams from different manufacturers used different formats, tag conventions, and data contracts as there was no shared schema, no common metadata, and no connection to the maintenance records or operational history that a predictive model needed. A model trained on raw sensor readings alone would have learned from noise. The work began not with algorithm selection, but with building the data foundation: unified ingestion pipelines, cross-system integration of sensor and maintenance data, and a feature engineering layer that gave the model the operational context it required. Only then did model building begin.
A sensor reading alone does not explain operating condition, equipment state, maintenance history, ore type, load, shift context, or failure mode. Without that context, a model is learning from noise.
This is also why so many mining AI pilots produce promising notebook results that never make it to production. The pilot was trained on a carefully prepared extract of historical data, cleaned and structured by a data scientist who understood the operational context. The production pipeline was never built to replicate that preparation at scale, in real time, with governance, access controls, and quality checks. The model worked. The infrastructure to sustain it did not exist.
What AI-ready mining data actually looks like
Enterprise AI data readiness in mining is not a single metric. It is a set of conditions that need to be true before a model can be trained, deployed, and trusted in production. Based on the CoffeeBeans AI Productionization framework, Stage 01 requires the following to be in place:
Source identification: Every data source relevant to the use case is known, mapped, and assessed for quality. This includes OT sources (historians, SCADA, DCS), IT sources (ERP, CMMS, fleet systems), and specialist sources (geological models, laboratory systems, ESG platforms).
Ingestion pipelines: Reliable, governed pipelines that move data from source to a centralised platform on a defined schedule, with logging, error handling, and alerting.
Storage architecture: A data architecture that can hold both historical and real-time data, with appropriate storage layers for raw, processed, and feature-ready data.
Schema management: Consistent naming conventions, data dictionaries, and metadata schemas across sources. A tag named PMP_001_FLOW in one historian and PUMP1_FLOWRATE in another describes the same thing. A model needs to know that.
Data quality and profiling: Automated checks that identify missing values, outliers, duplicate records, and schema violations before data enters the training pipeline.
Catalogue and discoverability: A data catalogue that allows engineers, data scientists, and operations teams to find, understand, and trust the data available to them.
Access controls and governance: Clear ownership of each data source, defined access permissions, and audit trails that establish who used which data and when.
None of these conditions requires new sensor investment. They require infrastructure, engineering, and governance work applied to data that already exists.
Why Stage 01 is the foundation for everything that follows
The CoffeeBeans AI Productionization Value Chain is a six-stage framework for moving AI from notebook to production. Stage 01, Data Readiness and Trust, is the first stage for a reason. Every subsequent stage depends on it.
Stage 02, Signal Creation and Data Prep, requires stable, trusted data sources that can be transformed into features consistently. Without Stage 01, feature pipelines break when source data changes, and models train on one version of reality while serving on another.
Stage 03, Model Building and Experimentation, requires reproducible training datasets. Without Stage 01, each experiment is built on a different data extract, and results cannot be compared or reproduced.
Stage 04, Pre-production sign-off and Stage 05, Model Deployment and Serving, requires production pipelines that replicate training conditions in real time. Without Stage 01, there is no governed pathway from raw operational data to model input.
Stage 06, Model Health and Performance, requires input data monitoring to detect when the data feeding a production model has changed in ways that affect accuracy. Without Stage 01, there is no baseline to monitor against.
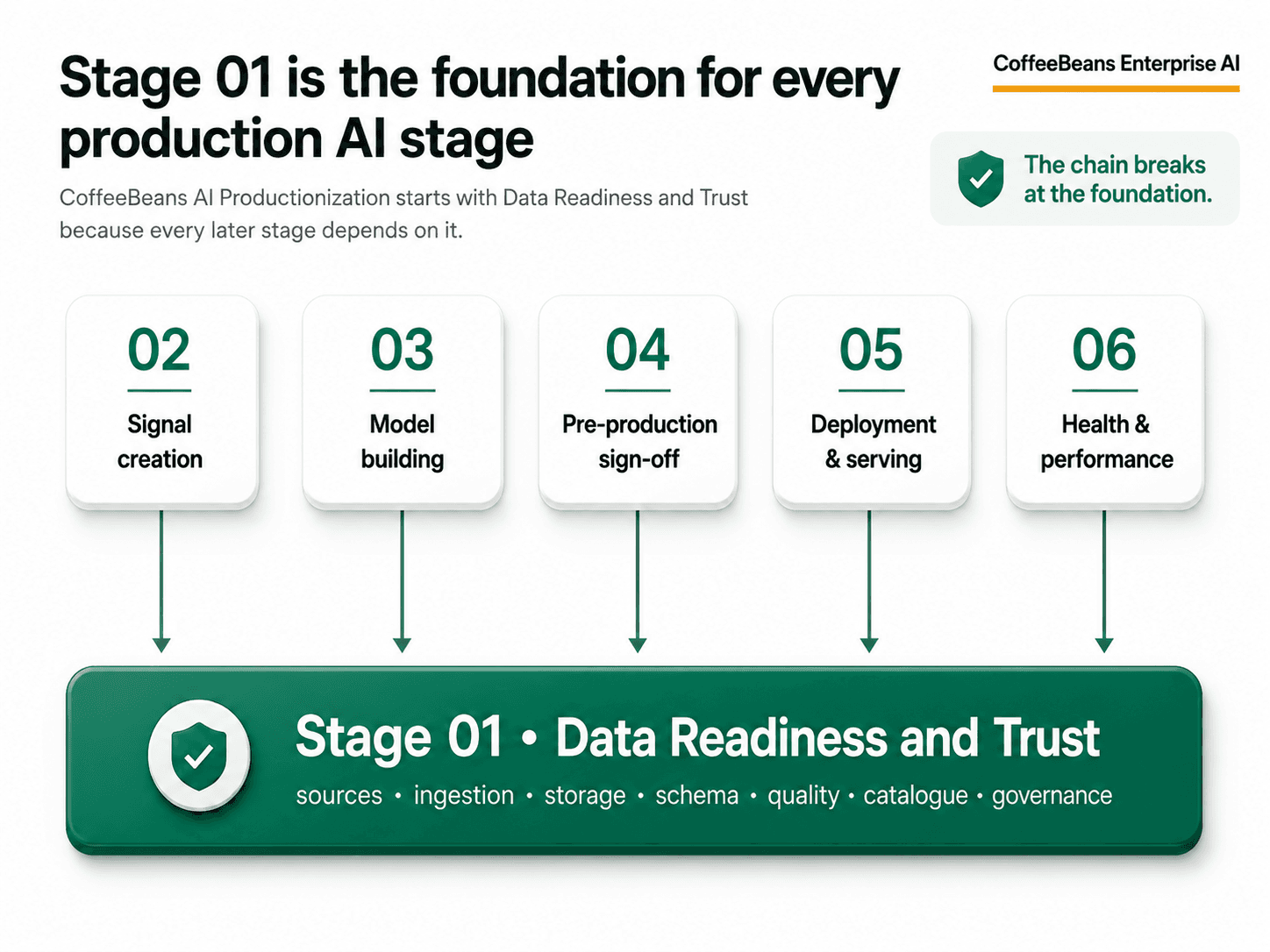
The chain breaks at the foundation. This is why mining AI projects that skip data readiness work so consistently fail to scale. The model is not the problem. The infrastructure underneath it is.
How CoffeeBeans helps build the mining AI data foundation
CoffeeBeans works with mining and industrial organisations to build the data foundations that make production AI possible. This is not generic data consulting. It is engineering work grounded in the operational realities of mines, processing plants, and the systems that run them.
Our industrial AI data strategy work typically begins with a structured assessment of the existing data landscape: what systems are in place, what data is being generated, how it is stored, how accessible it is, and how far it is from being AI-ready. From that starting point, we design and build the ingestion pipelines, storage architecture, governance frameworks, and quality checks that form the foundation for Stage 01.
The goal is not to replace operational systems. It is to build the layer that makes them useful to AI. Historians continue to do what historians do. Fleet systems continue to do what fleet systems do. What changes is that a governed, unified data layer now exists on top of them, and ML pipelines can be built on top of that.
For mining operations that have run pilots and are asking why they cannot scale, the answer is almost always in Stage 01. The model exists. The production infrastructure does not. CoffeeBeans starts there.
Ready to assess your mining AI data foundation?
If your operation is generating data but struggling to use it for AI, the gap is usually in Stage 01. CoffeeBeans can help you assess where your data foundation stands, identify the readiness gaps that are blocking production AI, and build the infrastructure to close them. Talk to our Enterprise AI practice about where your mining AI data strategy stands today.
Like What You’re Reading?
Subscribe to our newsletter to get the latest strategies, trends, and expert perspectives.
Similar Reads


Links
Company
Subscribe
Newsletter
Sign up to learn about AI in the business world.
© 2026 CoffeeBeans. All Rights Reserved.