The feature that worked perfectly in training and failed on night shift
Train/serve consistency in ML is the difference between a model that works in testing and one that holds up in production. Here is why it matters in mining

6
min read

A model is only as reliable as the pipeline that feeds it. Train/serve consistency is what determines whether a feature behaves the same way in production as it did during training — and whether the AI programme delivers the value the business case promised.
Of all the ways industrial AI programmes lose momentum, the one that is most expensive and least visible is this: a feature that behaved one way during model training behaves slightly differently in production. The model does not break. The dashboard does not flash red. The system continues to generate predictions. They simply become a little less reliable, and then a little less reliable, until the operations team stops trusting the output and quietly stops using it.
In machine learning terminology, this is called train/serve skew. The data or feature logic used to train the model does not match the data or feature logic that the production pipeline supplies to the model when it is running live. The model is operating on something subtly different from what it was taught.
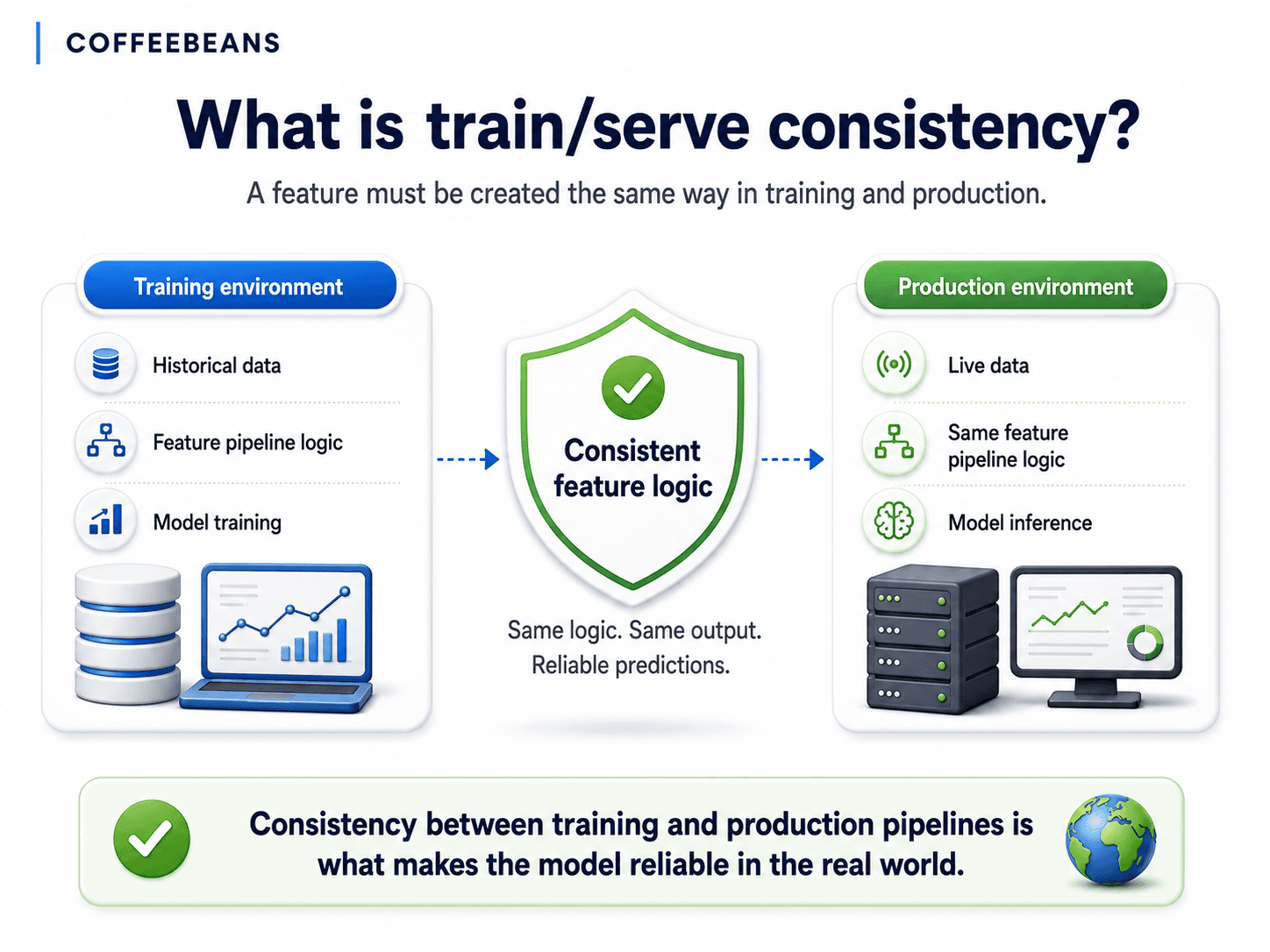
Over the last three articles, we have argued that mining operations rarely have a data shortage, that the historian is not the data foundation, and that raw sensor data is not a feature. This week, we go one layer deeper. Even when the signals are well-designed during training, the model can still fail in production if the production pipeline generates those signals differently from the training pipeline. This is the silent failure mode that industrial AI programmes most often miss.
|
What train/serve skew looks like in a mining environment
Subtle differences that no one notices until the model starts being wrong
In our experience, train/serve skew in industrial AI rarely arrives as a single dramatic failure. It accumulates from small mismatches that look harmless in isolation. A few examples will make the pattern concrete:
Window length mismatch. The vibration feature for a SAG mill bearing was computed as a 60-minute rolling average during training. In production, the streaming pipeline computes it over a 30-minute window because that is what the live ingestion logic supports. The same model is now consuming a fundamentally different feature.
Delayed sensor feeds. During training, the historian provided complete, end-of-day backfilled data. In production, the same sensor stream is delayed by several minutes during certain operating conditions. The feature is calculated on incomplete inputs.
Missing values handled differently. The training pipeline imputed missing crusher load readings with rolling averages. The production pipeline substitutes zeros. The model receives a value that was never part of its training distribution.
Operational definition changes. Truck cycle time was calculated in training with idle time excluded. In production, the streaming pipeline includes idle time. The feature is now measuring something different.
Labels that are not available in real time. A maintenance event flag was present in the training dataset because it was added retrospectively. In production, the flag arrives hours after the maintenance is logged. The model is making decisions without it.
Each of these mismatches is technical. None of them announces itself. All of them quietly degrade the value of AI investment.
Train/serve skew rarely announces itself. It usually shows up as quiet performance decay over weeks, not as a sudden alert.
Why production environments behave differently from training environments
Night shift is when the gap becomes visible
There is a reason train/serve skew tends to surface on night shift, during planned maintenance windows, or under abnormal operating conditions. Training data is, almost by definition, a curated version of operational reality. It is cleaned, gap-filled, time-aligned, and selected. Production reality is none of those things.

In a working mine or processing plant, sensors fail without warning. Data arrives late when network conditions deteriorate. Operators apply manual overrides that the streaming pipeline was not designed to handle. Maintenance events are logged inconsistently between shifts. Systems update at different frequencies. Night shift may apply different operational protocols from day shift. Each of these is normal operational behaviour. None of them appears in a clean training dataset, and none of them is handled gracefully by a feature pipeline that was not designed for it.
The result is that the model encounters input distributions in production that it never saw during training. The algorithm is doing what it was trained to do. The pipeline feeding it is supplying inputs the algorithm was never prepared for. The model output is technically correct relative to its training. It is operationally wrong relative to the situation in the plant.
|
Why the model does not fail loudly
Silent degradation is the defining property of train/serve skew
If train/serve skew caused models to crash, it would be a solved problem. The reason it remains the most common silent failure in industrial AI is that the model continues to function. It produces an output. The output is plausibly shaped. It can even be approximately right for many predictions. It is just less accurate, less timely, or less calibrated than it should be.

Operations teams notice this through experience long before any technical monitoring catches it. A predictive maintenance alert that used to be reliable starts triggering on assets that did not actually fail. A throughput optimization recommendation starts being ignored by the control room. Trust erodes. The AI programme starts to look like it has not delivered on its promise, when in fact the model is still capable. The pipeline feeding the model is the problem, and no one is looking there.
The issue is not always the model. In our experience, it is most often the pipeline feeding the model.
The leadership mistake that allows this to happen
Treating model validation as the finish line
The most common leadership mistake in industrial AI sequencing is to treat training validation metrics as evidence that the model is ready for production. The technical team reports strong accuracy on the test set. The proof of concept passes review. The model is approved for deployment. The question that does not get asked is the only question that determines whether the deployment will hold.
Can the same feature logic run reliably in production, on live data, under real operating conditions, every minute, for the next two years? That is the only meaningful validation. Training accuracy is necessary. It is not sufficient. A model that performs well on a curated test set and a model that performs well in a working mine are two different categories of asset, and they require two different kinds of validation.
For leadership teams, the implication is straightforward. The right diagnostic when reviewing an industrial AI deployment is not the training metric. It is whether the production feature pipeline has been engineered to match the training pipeline exactly, whether it has been tested against the operating conditions the production environment actually presents, and whether monitoring is in place to detect skew when it arrives.
|
What a reliable feature pipeline actually requires
The conditions that make train/serve consistency operationally true
A feature pipeline that holds in production has to satisfy a set of practical requirements. None of them is glamorous. All of them are necessary:
Shared feature definitions. The same logical specification governs how a feature is calculated in training and in serving. The specification is a controlled artifact, not a description in a notebook.
Consistent transformation logic. The code that calculates a feature in batch training is the same code, or a verified equivalent, of the code that calculates it in real-time serving.
Version-controlled pipeline code. Every change to feature logic is tracked, reviewed, and traceable. A feature that changed silently is a feature that will cause skew silently.
Time-window consistency. Rolling windows, lag intervals, and aggregation periods are identical across environments.
Missing value handling alignment. The strategy for imputing or filtering missing inputs is the same in both pipelines, and it is explicit, not implicit.
Data freshness and feature drift monitoring. Automated checks detect when input data arrives late, when feature distributions shift, or when a feature stops being produced.
End-to-end traceability. Every prediction can be traced back to the feature values that produced it, and every feature value can be traced back to the raw data that generated it.
Testing against edge cases. Shift transitions, manual overrides, sensor outages, and abnormal operating modes are tested explicitly before deployment, not discovered in production.
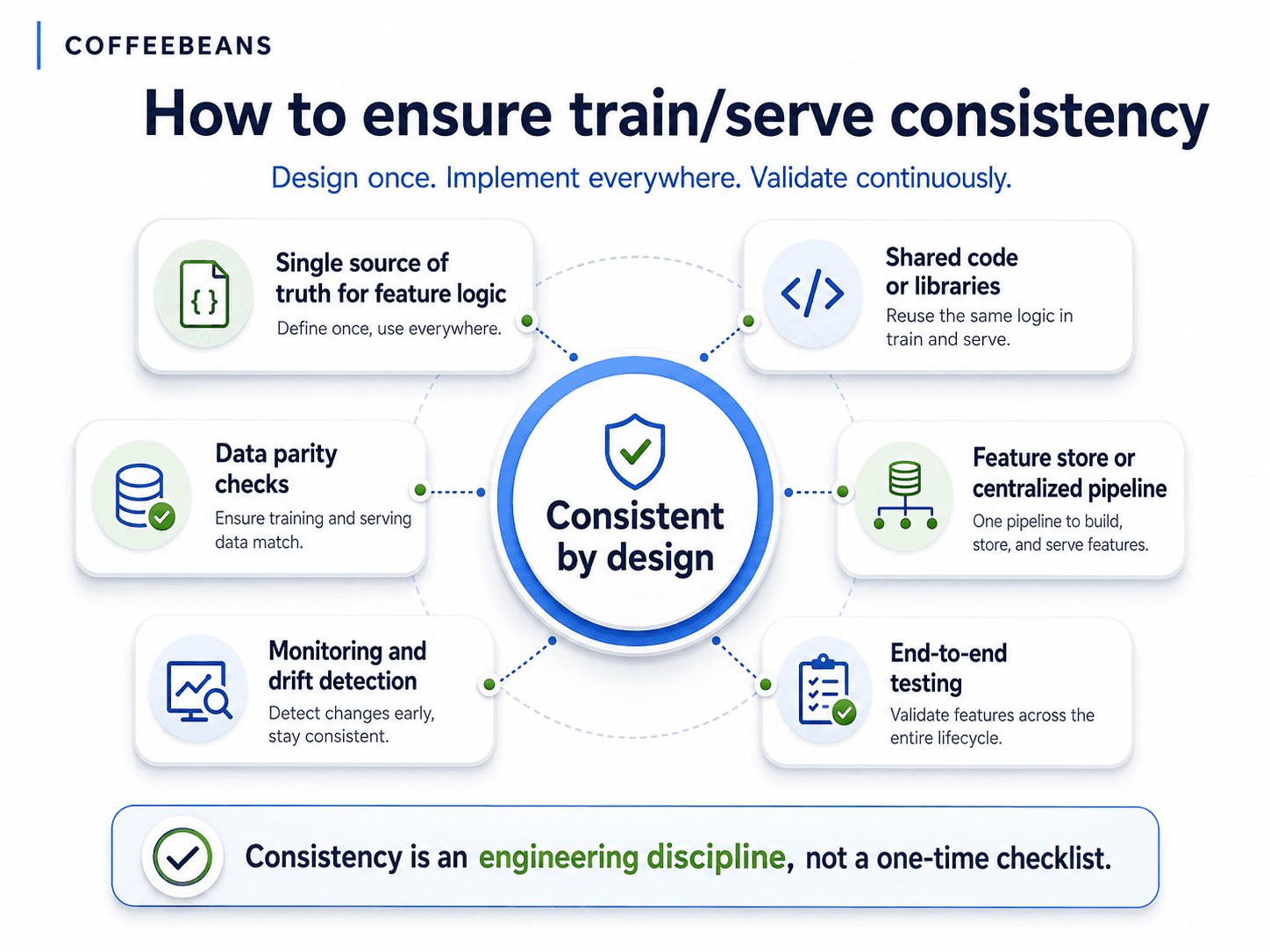
These are not nice-to-haves. They are the operational baseline for any industrial AI programme that intends to scale beyond a single pilot.
Why this connects to every stage of AI productionisation
Stage 02 is not a one-time activity
Stage 02 of the CoffeeBeans AI Productionization framework is not a step that is completed once and then handed off. Signal creation and data preparation is the ongoing infrastructure layer on which every later stage depends. When train/serve consistency is not engineered into Stage 02, every subsequent stage carries the cost.
Stage 03, Model Building and Experimentation, produces models that perform well in offline evaluation but are built on features that cannot be reproduced operationally. The experiment results are not portable to production.
Stage 04, Pre-Production Sign-off, cannot do its job. Shadow mode testing, edge case validation, and stress testing all depend on the production feature pipeline producing the same outputs as the training pipeline. If Stage 02 has not enforced consistency, Stage 04 will sign off on something that will fail.
Stage 05, Model Deployment and Serving, is where train/serve skew manifests most visibly. The model is technically deployed and serving predictions. The predictions are operationally unreliable. This is the most common single point of industrial AI failure that we encounter.
Stage 06, Model Health and Performance, requires a stable feature contract to monitor against. Without Stage 02 consistency, drift detection cannot distinguish between genuine model drift, data drift, and pipeline drift. All three look the same from the outside, and each requires a different response.
How CoffeeBeans helps
Engineering feature pipelines that hold under operational pressure
CoffeeBeans works with mining and industrial organisations to build feature pipeline production AI infrastructure that delivers consistent feature values in both training and live serving environments. Our train/serve consistency ML engagements focus on the structural causes of feature drift in industrial settings: differences in time-window logic, divergent missing-value handling, sensor delay tolerance, and operational conditions that the training pipeline never encountered.
From that foundation, our teams design and build the data pipeline machine learning infrastructure that makes the feature contract operationally enforceable. This includes shared transformation logic, version-controlled feature stores, feature freshness monitoring, distribution drift detection, and the regression tests that catch skew before it reaches operations. The objective is not a one-time deployment. The objective is an industrial AI programme that holds up across years of operating reality, including the conditions that the training environment never contained.
When industrial AI programmes lose trust with operations teams, the root cause is rarely the algorithm. It is the pipeline. CoffeeBeans builds the pipeline that survives production.
Is your production pipeline generating the same features your model was trained on?
If your industrial AI deployments are quietly losing accuracy or trust with operations teams, the root cause is often train/serve skew in the feature pipeline. CoffeeBeans can audit the consistency between your training and serving environments, identify where features are drifting, and build the data pipeline machine learning infrastructure that closes the gap. Talk to our Enterprise AI practice about train/serve consistency ML across your operation.
A model is only as reliable as the pipeline that feeds it. Train/serve consistency is what determines whether a feature behaves the same way in production as it did during training — and whether the AI programme delivers the value the business case promised.
Of all the ways industrial AI programmes lose momentum, the one that is most expensive and least visible is this: a feature that behaved one way during model training behaves slightly differently in production. The model does not break. The dashboard does not flash red. The system continues to generate predictions. They simply become a little less reliable, and then a little less reliable, until the operations team stops trusting the output and quietly stops using it.
In machine learning terminology, this is called train/serve skew. The data or feature logic used to train the model does not match the data or feature logic that the production pipeline supplies to the model when it is running live. The model is operating on something subtly different from what it was taught.
Over the last three articles, we have argued that mining operations rarely have a data shortage, that the historian is not the data foundation, and that raw sensor data is not a feature. This week, we go one layer deeper. Even when the signals are well-designed during training, the model can still fail in production if the production pipeline generates those signals differently from the training pipeline. This is the silent failure mode that industrial AI programmes most often miss.
|
What train/serve skew looks like in a mining environment
Subtle differences that no one notices until the model starts being wrong
In our experience, train/serve skew in industrial AI rarely arrives as a single dramatic failure. It accumulates from small mismatches that look harmless in isolation. A few examples will make the pattern concrete:
Window length mismatch. The vibration feature for a SAG mill bearing was computed as a 60-minute rolling average during training. In production, the streaming pipeline computes it over a 30-minute window because that is what the live ingestion logic supports. The same model is now consuming a fundamentally different feature.
Delayed sensor feeds. During training, the historian provided complete, end-of-day backfilled data. In production, the same sensor stream is delayed by several minutes during certain operating conditions. The feature is calculated on incomplete inputs.
Missing values handled differently. The training pipeline imputed missing crusher load readings with rolling averages. The production pipeline substitutes zeros. The model receives a value that was never part of its training distribution.
Operational definition changes. Truck cycle time was calculated in training with idle time excluded. In production, the streaming pipeline includes idle time. The feature is now measuring something different.
Labels that are not available in real time. A maintenance event flag was present in the training dataset because it was added retrospectively. In production, the flag arrives hours after the maintenance is logged. The model is making decisions without it.
Each of these mismatches is technical. None of them announces itself. All of them quietly degrade the value of AI investment.
Train/serve skew rarely announces itself. It usually shows up as quiet performance decay over weeks, not as a sudden alert.
Why production environments behave differently from training environments
Night shift is when the gap becomes visible
There is a reason train/serve skew tends to surface on night shift, during planned maintenance windows, or under abnormal operating conditions. Training data is, almost by definition, a curated version of operational reality. It is cleaned, gap-filled, time-aligned, and selected. Production reality is none of those things.
In a working mine or processing plant, sensors fail without warning. Data arrives late when network conditions deteriorate. Operators apply manual overrides that the streaming pipeline was not designed to handle. Maintenance events are logged inconsistently between shifts. Systems update at different frequencies. Night shift may apply different operational protocols from day shift. Each of these is normal operational behaviour. None of them appears in a clean training dataset, and none of them is handled gracefully by a feature pipeline that was not designed for it.
The result is that the model encounters input distributions in production that it never saw during training. The algorithm is doing what it was trained to do. The pipeline feeding it is supplying inputs the algorithm was never prepared for. The model output is technically correct relative to its training. It is operationally wrong relative to the situation in the plant.
|
Why the model does not fail loudly
Silent degradation is the defining property of train/serve skew
If train/serve skew caused models to crash, it would be a solved problem. The reason it remains the most common silent failure in industrial AI is that the model continues to function. It produces an output. The output is plausibly shaped. It can even be approximately right for many predictions. It is just less accurate, less timely, or less calibrated than it should be.
Operations teams notice this through experience long before any technical monitoring catches it. A predictive maintenance alert that used to be reliable starts triggering on assets that did not actually fail. A throughput optimization recommendation starts being ignored by the control room. Trust erodes. The AI programme starts to look like it has not delivered on its promise, when in fact the model is still capable. The pipeline feeding the model is the problem, and no one is looking there.
The issue is not always the model. In our experience, it is most often the pipeline feeding the model.
The leadership mistake that allows this to happen
Treating model validation as the finish line
The most common leadership mistake in industrial AI sequencing is to treat training validation metrics as evidence that the model is ready for production. The technical team reports strong accuracy on the test set. The proof of concept passes review. The model is approved for deployment. The question that does not get asked is the only question that determines whether the deployment will hold.
Can the same feature logic run reliably in production, on live data, under real operating conditions, every minute, for the next two years? That is the only meaningful validation. Training accuracy is necessary. It is not sufficient. A model that performs well on a curated test set and a model that performs well in a working mine are two different categories of asset, and they require two different kinds of validation.
For leadership teams, the implication is straightforward. The right diagnostic when reviewing an industrial AI deployment is not the training metric. It is whether the production feature pipeline has been engineered to match the training pipeline exactly, whether it has been tested against the operating conditions the production environment actually presents, and whether monitoring is in place to detect skew when it arrives.
|
What a reliable feature pipeline actually requires
The conditions that make train/serve consistency operationally true
A feature pipeline that holds in production has to satisfy a set of practical requirements. None of them is glamorous. All of them are necessary:
Shared feature definitions. The same logical specification governs how a feature is calculated in training and in serving. The specification is a controlled artifact, not a description in a notebook.
Consistent transformation logic. The code that calculates a feature in batch training is the same code, or a verified equivalent, of the code that calculates it in real-time serving.
Version-controlled pipeline code. Every change to feature logic is tracked, reviewed, and traceable. A feature that changed silently is a feature that will cause skew silently.
Time-window consistency. Rolling windows, lag intervals, and aggregation periods are identical across environments.
Missing value handling alignment. The strategy for imputing or filtering missing inputs is the same in both pipelines, and it is explicit, not implicit.
Data freshness and feature drift monitoring. Automated checks detect when input data arrives late, when feature distributions shift, or when a feature stops being produced.
End-to-end traceability. Every prediction can be traced back to the feature values that produced it, and every feature value can be traced back to the raw data that generated it.
Testing against edge cases. Shift transitions, manual overrides, sensor outages, and abnormal operating modes are tested explicitly before deployment, not discovered in production.
These are not nice-to-haves. They are the operational baseline for any industrial AI programme that intends to scale beyond a single pilot.
Why this connects to every stage of AI productionisation
Stage 02 is not a one-time activity
Stage 02 of the CoffeeBeans AI Productionization framework is not a step that is completed once and then handed off. Signal creation and data preparation is the ongoing infrastructure layer on which every later stage depends. When train/serve consistency is not engineered into Stage 02, every subsequent stage carries the cost.
Stage 03, Model Building and Experimentation, produces models that perform well in offline evaluation but are built on features that cannot be reproduced operationally. The experiment results are not portable to production.
Stage 04, Pre-Production Sign-off, cannot do its job. Shadow mode testing, edge case validation, and stress testing all depend on the production feature pipeline producing the same outputs as the training pipeline. If Stage 02 has not enforced consistency, Stage 04 will sign off on something that will fail.
Stage 05, Model Deployment and Serving, is where train/serve skew manifests most visibly. The model is technically deployed and serving predictions. The predictions are operationally unreliable. This is the most common single point of industrial AI failure that we encounter.
Stage 06, Model Health and Performance, requires a stable feature contract to monitor against. Without Stage 02 consistency, drift detection cannot distinguish between genuine model drift, data drift, and pipeline drift. All three look the same from the outside, and each requires a different response.
How CoffeeBeans helps
Engineering feature pipelines that hold under operational pressure
CoffeeBeans works with mining and industrial organisations to build feature pipeline production AI infrastructure that delivers consistent feature values in both training and live serving environments. Our train/serve consistency ML engagements focus on the structural causes of feature drift in industrial settings: differences in time-window logic, divergent missing-value handling, sensor delay tolerance, and operational conditions that the training pipeline never encountered.
From that foundation, our teams design and build the data pipeline machine learning infrastructure that makes the feature contract operationally enforceable. This includes shared transformation logic, version-controlled feature stores, feature freshness monitoring, distribution drift detection, and the regression tests that catch skew before it reaches operations. The objective is not a one-time deployment. The objective is an industrial AI programme that holds up across years of operating reality, including the conditions that the training environment never contained.
When industrial AI programmes lose trust with operations teams, the root cause is rarely the algorithm. It is the pipeline. CoffeeBeans builds the pipeline that survives production.
Is your production pipeline generating the same features your model was trained on?
If your industrial AI deployments are quietly losing accuracy or trust with operations teams, the root cause is often train/serve skew in the feature pipeline. CoffeeBeans can audit the consistency between your training and serving environments, identify where features are drifting, and build the data pipeline machine learning infrastructure that closes the gap. Talk to our Enterprise AI practice about train/serve consistency ML across your operation.
Like What You’re Reading?
Subscribe to our newsletter to get the latest strategies, trends, and expert perspectives.
Similar Reads



Links
Subscribe
Newsletter
Sign up to learn about AI in the business world.
© 2026 CoffeeBeans. All Rights Reserved.