It passed the demo. That was the only test it got.
AI model testing enterprise discipline goes beyond demos. Edge case testing, bias audits, and stress tests prove production readiness for mining and industrial AI

6
min read

A successful demo proves the model can produce a convincing result under controlled conditions. Production readiness has to be proven against the conditions under which the model can fail.
Most AI programmes have a demo moment. The model is shown working on a carefully chosen example. The dashboard is clean. The alerts make sense. The narrative is clear. Leadership leaves the room confident, and the next conversation is about deployment. In our experience working with mining and industrial organisations, this is the moment when the most consequential mistake in enterprise AI is made. The demo is mistaken for a test.
Last week, we argued that pre-production sign-off is the discipline that separates a tested model from a deployable one. This week, we go deeper into what that discipline must actually include. A demo shows the model under conditions the team chose. A working SAG mill, a primary crusher, a conveyor system, or a haul truck fleet does not let the team choose the conditions. Production environments present whatever the operation presents — sensor outages, delayed feeds, abnormal ore characteristics, post-maintenance startup, shift handovers, manual overrides, and the constant operational improvisation that defines a working plant. None of these are visible in a demo. All of them affect the model in production.
The discipline that closes this gap is AI model testing enterprise practice. Not testing for accuracy on a held-out sample, which is necessary but inadequate. Testing for the failure modes a working operation will produce, before the operation has to discover them.
|
Why demos feel convincing but are not enough
The conditions a demo selects are not the conditions production presents
Demos are useful. They align stakeholders, build confidence in the work, and create the political conditions for deployment. They are also, by design, incomplete. A demo is constructed. It uses clean historical data, a coherent narrative, a favourable scenario, and a clear ending. None of these conditions are present in production.
In our experience, the conditions a demo typically does not show are the conditions that decide whether an industrial AI model succeeds after go-live:
Missing or delayed data. The historian tag the model depends on arrives ten minutes late during specific operating conditions. The demo used end-of-day data, which was complete.
Faulty sensor values. A vibration sensor reports plausible but inaccurate readings after a maintenance event. The demo used clean data, where this never happened.
Rare operating modes. The SAG mill processes a softer ore blend that the training data underrepresented. The demo used a typical operating envelope.
Shift-level differences. Operators on night shift apply protocols slightly differently from day shift. The demo used aggregated data that obscured this.
False positive burden. The model produces three actionable alerts per day in the demo and twenty per day in production. Maintenance teams stop responding.
Unclear ownership when the model is wrong. The demo did not need to address this. Production cannot avoid it.

The model should be tested against the conditions under which it can fail, not only the conditions under which it performs well.
Edge case testing in mining operations
Edge cases are not exceptions in industrial AI. They are part of normal operations.
Edge case testing AI industrial practice is the structured exposure of a candidate model to unusual but entirely realistic operating conditions before deployment. In a mining environment, the relevant edge cases are not hypothetical. They occur regularly, sometimes daily, and the model will encounter them whether or not the team prepared it for them. The question is whether the team finds out under controlled conditions or after the model is influencing operational decisions.
Edge cases that should be tested explicitly in industrial AI include:
A conveyor running under abnormal load. Operating conditions that fall outside the typical envelope but are not malfunctions.
A crusher operating in the period immediately after maintenance. Behaviour during run-up and stabilisation differs structurally from steady-state operation.
A SAG mill processing a different ore blend. The model trained on one mineralogical profile may behave unpredictably on another.
A pump with intermittent sensor gaps. Sensor reliability varies across asset age and instrumentation quality.
A fleet optimisation model during weather disruption. Visibility, road conditions, and operator behaviour change in ways the training data may not reflect.
A maintenance model during night shift operations. Different staffing, different escalation paths, different operational rhythms.

Each of these is a normal part of a working operation. None of them is an exception. A model that has not been tested against them is a model that will encounter them for the first time in production, which is the wrong place to discover how it behaves.
|
Stress testing the model and the pipeline
The algorithm is rarely the bottleneck. The infrastructure around it often is.
Stress testing in industrial AI is not only about the algorithm. It is equally about the data pipeline and the operational workflow that the model depends on. A model that performs well at five inference calls per minute may struggle at five hundred. A pipeline that handles complete data gracefully may fail silently when fields are missing. A workflow that processes one alert at a time may collapse when multiple assets produce alerts simultaneously.
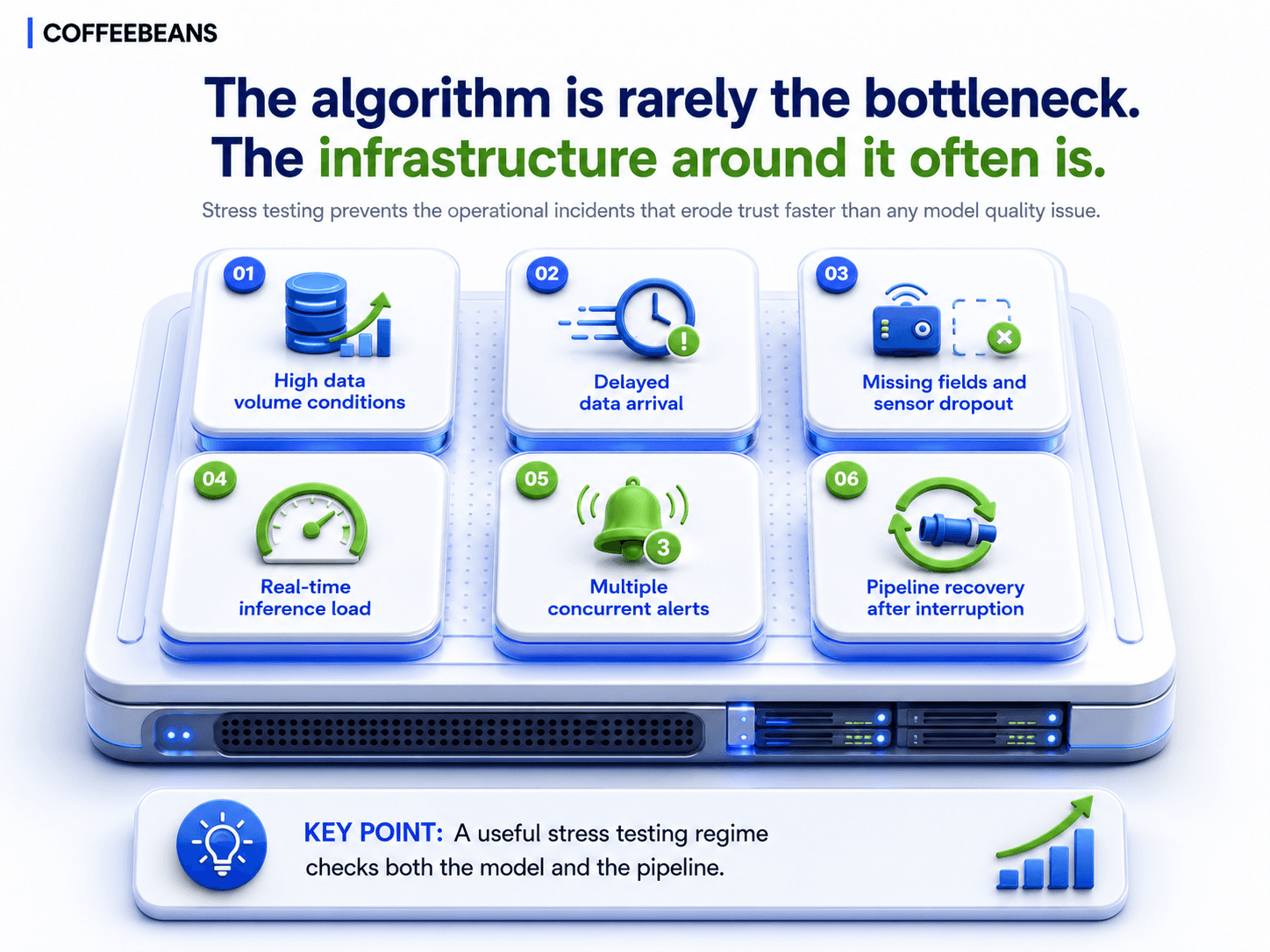
A useful stress testing regime for industrial AI should include:
High data volume conditions — to confirm the pipeline can serve at peak load.
Delayed data arrival — to confirm the model behaves sensibly when its inputs are not yet complete.
Missing fields and sensor dropout — to confirm the imputation strategy holds.
Real-time inference load — to confirm latency targets are met under realistic concurrency.
Multiple concurrent alerts — to confirm the operational workflow can route and prioritise.
Pipeline recovery after interruption — to confirm the system returns to a known-good state.
Stress testing is not glamorous. It is the discipline that prevents the operational incidents that erode trust faster than any model quality issue. Operations teams will forgive a model that occasionally misses a prediction. They are less forgiving of a system that produces a hundred conflicting alerts during a busy shift.
Bias audits in industrial AI
Bias in industrial ML rarely looks the way bias looks in consumer AI
Bias audit machine learning practice in industrial AI is structurally different from the bias conversations that dominate public discourse around consumer AI. In a mining context, bias is rarely about demographic groups. It is about systematic differences in how the model performs across asset classes, operating conditions, shifts, instrumentation quality, and data coverage. A model that performs well on average but fails reliably on a specific subset of conditions is a biased model, even if no protected characteristic is involved.
Bias in industrial ML can appear when the model performs systematically better for:
Some asset types more than others. The model may have learned a pattern that holds for newer assets but not for older ones with different wear profiles.
Day shift than night shift. The training data may overrepresent one shift's operating protocols.
Well-instrumented equipment than older assets. Data-rich assets contribute more to learning, which can skew performance.
Certain operating modes. Steady-state may be well-represented; startup, shutdown, and transition states may not be.
Certain failure types. Failure modes that have occurred more frequently in the historical record dominate what the model has learned.
Data-rich sites compared with data-poor sites. In multi-site deployments, the model may quietly favour the sites whose data shaped the training.
Bias audits surface these differences. They do not necessarily eliminate them. What they do is make explicit where the model can be trusted, where it cannot yet be trusted, and which subsets of operation require further work before the model is allowed to influence decisions in those conditions.
Bias in industrial AI is rarely visible at the headline accuracy number. It is visible only when performance is decomposed across asset, shift, operating mode, and site.

The seven tests an industrial AI model should pass before go-live
A practical checklist for the pre-production sign-off conversation
Across the engagements we have led, the following seven tests represent the minimum validation regime an industrial AI model should pass before deployment. None of these tests is theoretical. Each one prevents a specific failure mode we have seen in production.
Test | What it confirms before go-live | |
1 | Data quality test | Confirms that data feeding the live pipeline matches the freshness, completeness, and consistency of the training data. |
2 | Feature pipeline consistency test | Verifies that production features are calculated identically to training features. The Stage 02 train/serve check executed at deployment time. |
3 | Edge case test | Exposes the model to unusual but realistic operating conditions: sensor gaps, abnormal load, post-maintenance startup, ore blend changes, shift transitions. |
4 | Stress test | Tests the model and pipeline under high data volume, delayed feeds, multiple concurrent alerts, and recovery from interruption. |
5 | Bias and coverage audit | Confirms whether the model performs consistently across asset classes, shifts, operating modes, and data-rich versus data-poor environments. |
6 | Shadow mode test | Runs the model in parallel with live operations without driving decisions, allowing observation of model behaviour under real plant conditions. |
7 | Human review and business readiness test | Confirms that operations, maintenance, and reliability leaders find the output operationally sensible, actionable, and accountable. |
This list is not exhaustive. It is the floor. In high-consequence settings — safety-critical predictive maintenance, real-time process optimisation, autonomous fleet decision support — additional discipline is warranted. But no industrial AI model should go live without these seven tests completed and documented.
|
The leadership mistake we see repeatedly
Confusing demo confidence with deployment readiness
The most common leadership question at this stage of an industrial AI programme is, did the demo work? The question is reasonable. It is also the wrong gating question for deployment. A demo working confirms that the model can produce a coherent result on selected data. It does not confirm anything about how the model will behave under the conditions the operation will actually present.
The better question, every time, is this: what failure modes have we tested, and what did we learn? If the team can answer that question with specific reference to edge cases, stress conditions, bias audits, shadow mode observations, and human reviews, the deployment is on credible ground. If the team can only point to the demo and standard accuracy metrics, the deployment is exposed, regardless of how strong those metrics appear.
How Stage 04 connects to deployment and beyond
The validation completed here is what makes Stages 05 and 06 possible
Stage 04 of the CoffeeBeans AI Productionization Value Chain is not complete when the model has been technically validated. It is complete when it has been tested against the failure modes a working operation produces, reviewed by the operational stakeholders who will rely on it, and approved against documented go/no-go criteria. Skipping any of these turns the cost into Stage 05 and Stage 06 problems.
Stage 05, Model Deployment and Serving, inherits a model whose behaviour under operational conditions has not been confirmed. Rollback cycles and remediation efforts become routine. Operations teams lose confidence faster than the team can rebuild it.
Stage 06, Model Health and Performance, begins without a confirmed operational baseline. When performance changes, the team cannot distinguish whether the model is drifting or whether the model was never appropriate for this segment of the operation to begin with.
Done properly, Stage 04 prevents both failure modes. It is the most underused control in industrial AI, and it is the single highest-leverage one.
How CoffeeBeans helps
Designing pre-production testing that survives operational reality
CoffeeBeans works with mining and industrial organisations to build AI model testing enterprise discipline into the productionisation chain. Our Stage 04 engagements typically begin with the design of the testing framework itself: which edge cases apply to each use case, what stress scenarios reflect the operational reality of the plant, what bias dimensions matter for the asset mix in question, and how the results of each test feed into the documented go/no-go decision.
From there, we operationalise the testing. Edge case testing AI industrial scenarios are constructed against the specific failure modes the operation has experienced historically. Bias audit machine learning decomposition is structured around the asset classes, shifts, operating modes, and sites the model will serve. Stress testing is configured to represent realistic concurrency and load. Shadow mode testing is set up against live operational data. And human review gates are designed to be substantive without becoming bureaucratic.
The objective is straightforward. When an industrial AI model goes live, the operations team should be able to answer a simple question: what failure modes have we tested for, and how did the model perform? When that answer is concrete and specific, the deployment is on solid ground. When it is not, the deployment is exposed. CoffeeBeans builds the discipline that makes the answer concrete.
Has your AI model been tested, or has it only been demonstrated?
If your industrial AI programme is approaching deployment on the strength of strong demo metrics and a standard accuracy number, the gap is in the testing discipline. CoffeeBeans can help your team design the AI model testing enterprise framework, structure the edge case testing AI industrial scenarios that reflect your operation, and embed the bias audit machine learning decomposition that production readiness requires. Talk to our Enterprise AI practice about pre-production testing in your operation.
Like What You’re Reading?
Subscribe to our newsletter to get the latest strategies, trends, and expert perspectives.
Similar Reads


Links
Subscribe
Newsletter
Sign up to learn about AI in the business world.
© 2026 CoffeeBeans. All Rights Reserved.