Predicting equipment failure at a SAG mill: why the algorithm is the easy part
Predictive maintenance in mining is more than algorithms. SAG mill failure prediction requires baselines, class imbalance handling, experiment tracking, and reproducibility

6
min read

Predictive maintenance in mining depends less on model choice and more on failure definition, data quality, baseline rigour, class imbalance handling, experiment tracking, and reproducibility. The algorithm is rarely the bottleneck.
There is a familiar moment in most industrial AI conversations. A leadership team has decided that predictive maintenance is the right place to start. The use case is well-chosen. A SAG mill is identified as the asset. The question that follows, almost without exception, is this: which algorithm should we use? In our experience working with mining organisations, this is rarely the most important question. It is also rarely the question that determines whether the programme succeeds.
This week, we focus on a concrete case. A SAG mill is one of the most heavily instrumented and operationally critical assets in any processing plant. Vibration, power draw, throughput, bearing temperature, lubrication condition, feed characteristics, and operating mode are all available in some form. Failure is expensive. Downtime cascades through the plant. The business case for predictive maintenance is strong. And yet, in our experience, more SAG mill predictive maintenance projects stall in Stage 03, Model Building and Experimentation, than in any other stage. The algorithm is almost never the reason.

|
The first question is not which algorithm to use
It is what exactly the model is being asked to predict
Predictive maintenance is not a single problem. It is a category of problems, each of which requires different labels, time windows, evaluation metrics, and operational responses. Before any model is built, leadership and the technical team need to agree on what is actually being predicted.
Failure within the next 24 hours. A short-horizon classification problem that demands high precision and a clear maintenance response path.
Abnormal condition within the next shift. A medium-horizon problem aligned with shift handover and operational planning cycles.
Component degradation risk. A regression or probability problem that informs maintenance scheduling rather than immediate intervention.
Probability of unplanned stoppage in a defined window. A probabilistic output that integrates with production planning.
Remaining useful life of a specific component. A long-horizon estimation problem that requires extensive historical data and consistent component-level tracking.
Each of these targets requires different labels, different data windows, different evaluation metrics, and different operational integration. A model trained to predict failure within 24 hours cannot be repurposed to estimate remaining useful life. The conversation about algorithm choice is not meaningful until this question has been answered.
If failure is poorly defined, the model will learn the wrong problem with high accuracy. That is the most expensive outcome in industrial AI.
Why baseline definition matters more than most teams expect
A model is only valuable if it outperforms what the operation already uses
Mining operations rarely arrive at predictive maintenance with nothing in place. There is usually a planned maintenance schedule, rule-based threshold alerting, operator judgement built up over many years, and historical failure rate data. These represent the operational baseline. Any predictive model has to outperform that baseline in a way the operations team finds practically useful.

In our experience, the most common error in Stage 03 is the absence of a defined baseline. The model is evaluated against itself: it achieves 92 percent accuracy, the team declares success, and the project moves forward. The question that does not get asked is what the existing maintenance regime would have achieved on the same dataset. Without that comparison, the business case is incomplete. A complex model that performs marginally better than a simple statistical rule is not a strategic asset. A simpler model that materially improves on rule-based alerting is.
For leadership teams, the practical implication is that Stage 03 evaluation must include the baseline. The relevant question is not how accurate is the model? The relevant question is how much better is it than what we are doing today, and is the difference worth the cost of operating it in production?
|
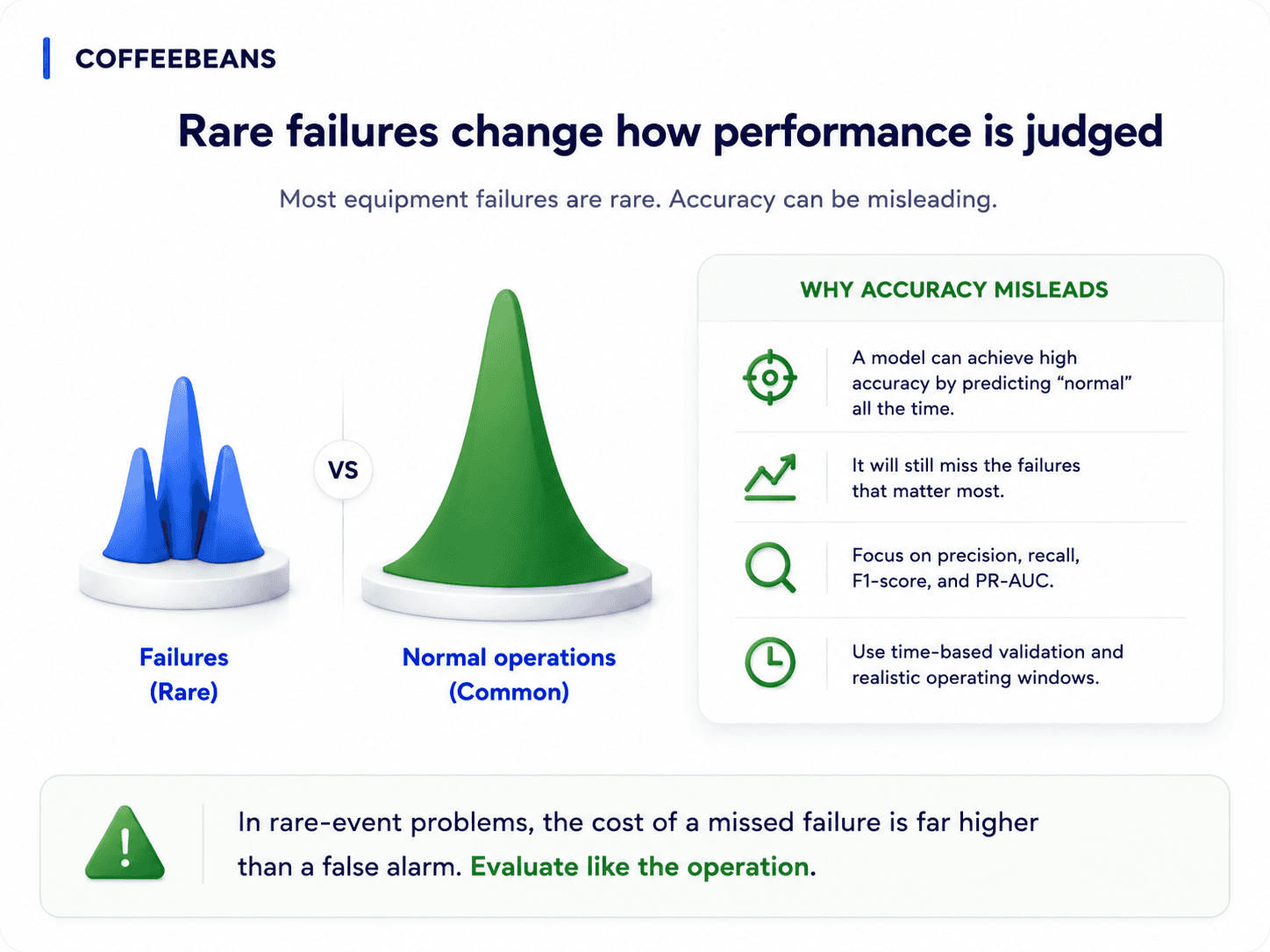
The class imbalance problem in equipment failure prediction
Failures are rare, which changes how performance must be judged
A SAG mill in a well-run processing plant fails infrequently. That is precisely the operational outcome the plant is engineered to deliver. From a machine learning perspective, this creates a structural problem. Across years of operating data, perhaps 99 percent of records correspond to normal operation, with failure events scattered thinly across the remaining one percent. This is class imbalance, and it changes the entire framing of how model performance should be evaluated.
A model that predicts 'no failure' at every timestamp will achieve approximately 99 percent accuracy on this dataset. It will also be operationally useless. Accuracy, taken alone, is a misleading metric in any predictive maintenance context.
Metric the model team often defaults to | Metric the business actually needs |
Overall accuracy | Precision: when the model predicts failure, how often is it right? |
AUC on a balanced sample | Recall: of all actual failures, how many did the model catch? |
Cross-validation average score | Cost of false positives in maintenance hours and lost confidence |
F1 on a synthetic balanced set | Cost of false negatives in unplanned downtime and damage |
Lead time: how far in advance does the model give warning? |
Equipment failure prediction is fundamentally a business problem expressed as a machine learning problem. The cost of a false positive (an unnecessary maintenance intervention) is rarely the same as the cost of a false negative (a missed failure leading to unplanned downtime). The model has to be optimised against the actual operational cost function, not a generic statistical metric. This is a conversation between data scientists, maintenance leaders, and operations heads, not a technical decision made in isolation.
|
Why experiment tracking is a governance requirement, not a technical preference
A model that cannot be reproduced cannot be trusted in production
In a working SAG mill predictive maintenance programme, the data science team will run hundreds of experiments before a candidate model emerges. Different feature sets, different time windows, different label definitions, different algorithms, different parameters, different evaluation conditions. Without disciplined experiment tracking, none of this work is recoverable. The model that performed best three months ago cannot be reproduced. The features that drove its performance cannot be confirmed. The evaluation that justified its selection cannot be audited.
Production-grade experiment tracking captures, at minimum, the following:
Dataset version. The exact data extract used, with provenance back to the source systems.
Feature set. The version of the feature pipeline that produced the inputs.
Label definition. How failure was defined and how labels were constructed.
Time window. The training, validation, and test periods.
Algorithm and parameters. The model type and the full configuration used.
Evaluation metrics. Against the agreed business cost function, not just statistical defaults.
Training date and environment. Including code version and library versions.
Business outcome being measured. Tied to the operational metric the model is meant to improve.
A model that cannot be reproduced cannot be governed, audited, or productionised. It is a research artefact, not a production asset.
Why the notebook is not the finish line
Stage 03 is the bridge to production, not a destination
There is a recurring pattern in industrial AI programmes that we encounter repeatedly. A senior data scientist produces a strong predictive maintenance model in a notebook. The model performs well. The notebook is impressive. Six months later, the team has been unable to deploy it. The reasons are almost never about the algorithm but the operational infrastructure that the notebook was never built to provide.

A production-ready predictive maintenance model requires versioned data, versioned features, tracked experiments, reproducible training pipelines, a model registry, a validation process, a defined deployment path, and a monitoring plan. The notebook contains none of these by default. Stage 03, done properly, produces all of them as natural artefacts of the model building process.
This is the structural reason that Stage 03 cannot be separated from Stage 04, Stage 05, and Stage 06. Pre-production sign-off (Stage 04) requires reproducible experiments to validate against. Deployment and serving (Stage 05) requires a model registry and versioned artefacts. Model health monitoring (Stage 06) requires the original evaluation baseline to monitor performance against. A model built without these disciplines will struggle at every later stage, regardless of how well it performed in the original experiment.
|
How CoffeeBeans helps
Building predictive maintenance models that survive contact with the plant
CoffeeBeans works with mining operations to build predictive maintenance mining programmes that move beyond promising proofs of concept and into governed production. Our SAG mill AI engagements begin not with algorithm selection, but with structured workshops involving operations leaders, maintenance heads, and data engineering teams to define the failure problem precisely: what is being predicted, on what horizon, with what business cost function, and against what baseline.
From there, our teams build the equipment failure prediction machine learning pipeline as a production system from the outset. Experiments are tracked. Datasets and features are versioned. Class imbalance is handled deliberately rather than papered over. Evaluation is conducted against the business cost function the operation actually faces. Reproducibility is engineered into the workflow, not retrofitted after the fact. The objective is not a notebook that demonstrates a model. The objective is a model registry artefact that can be validated in Stage 04, deployed in Stage 05, and monitored in Stage 06 without rework.
When predictive maintenance programmes stall, the cause is almost never the algorithm. It is the discipline of the experiment that produced it. CoffeeBeans builds that discipline into the work from the first day.
Is your predictive maintenance model a notebook, or a production asset?
If your team has a SAG mill predictive maintenance model that performs well in evaluation but has not yet reached the plant, the gap is rarely in the algorithm. It is in problem definition, baseline rigour, class imbalance handling, and experiment governance. CoffeeBeans can assess where your SAG mill AI programme stands, identify the Stage 03 gaps that are blocking production, and build the experimentation discipline that predictive maintenance mining requires to scale. Talk to our Enterprise AI practice about equipment failure prediction machine learning in your operation.
Like What You’re Reading?
Subscribe to our newsletter to get the latest strategies, trends, and expert perspectives.
Similar Reads



Links
Subscribe
Newsletter
Sign up to learn about AI in the business world.
© 2026 CoffeeBeans. All Rights Reserved.