Your data scientist ran 200 experiments. Nobody can reproduce any of them.
MLflow experiment tracking and model registry discipline turn informal ML experimentation into governed, reproducible production AI. Here is why it matters in mining

6
min read

Experiment tracking is what turns model exploration into production-ready enterprise ML. Without it, the number of experiments run becomes a measure of activity, not progress.
There is a particular slide that appears in many industrial AI programme updates. It reports the number of experiments the data science team has run over the past quarter. The number is impressive. Two hundred runs. Three hundred runs. Sometimes more. The slide is intended to demonstrate momentum. In our experience, it often reveals the opposite.
The question that should follow that number is rarely asked. Of those two hundred experiments, which one produced the best model? Can the team identify the dataset version, the feature definitions, the parameters, the code commit, and the evaluation logic that produced that result? Can a different team member reproduce it tomorrow? Can it be reproduced in six months, when the original data scientist has moved on? When the honest answer is no, the experimentation does not progress. It is exposure.
Over the last five articles in this series, we have argued that mining operations have a data readiness problem rather than a data shortage, that the historian is not the data foundation, that raw sensor data is not a feature, that train/serve consistency determines whether features hold in production, and that in predictive maintenance the algorithm is rarely the hardest part. This week, we focus on the second half of Stage 03 of the CoffeeBeans AI Productionization Value Chain. A model that cannot be reproduced is not yet a model that can be productionised.
|
What informal experimentation actually looks like
A pattern that is universal, familiar, and operationally dangerous
In our experience working with mining and industrial organisations, informal experimentation follows a remarkably consistent pattern. The technical work is competent. The discipline around it is not.
Notebooks with names like model_v3, model_v3_final, and model_v3_final_actual. The author knows which one is current. Nobody else does.
Datasets cleaned locally in a way that was never documented. Six months later, no one can confirm which rows were dropped or which outliers were excluded.
Feature definitions that exist only in code. If the code changes, the feature definition changes silently with it.
Metrics captured by screenshot. The evaluation results are saved as images, not as structured data tied to a specific experiment.
Parameters changed manually between runs without logs. When a particular run performs well, the team cannot recover the exact configuration that produced it.
Multiple files claiming to be the final model. The model artefact in production may or may not match the experiment that justified its selection.
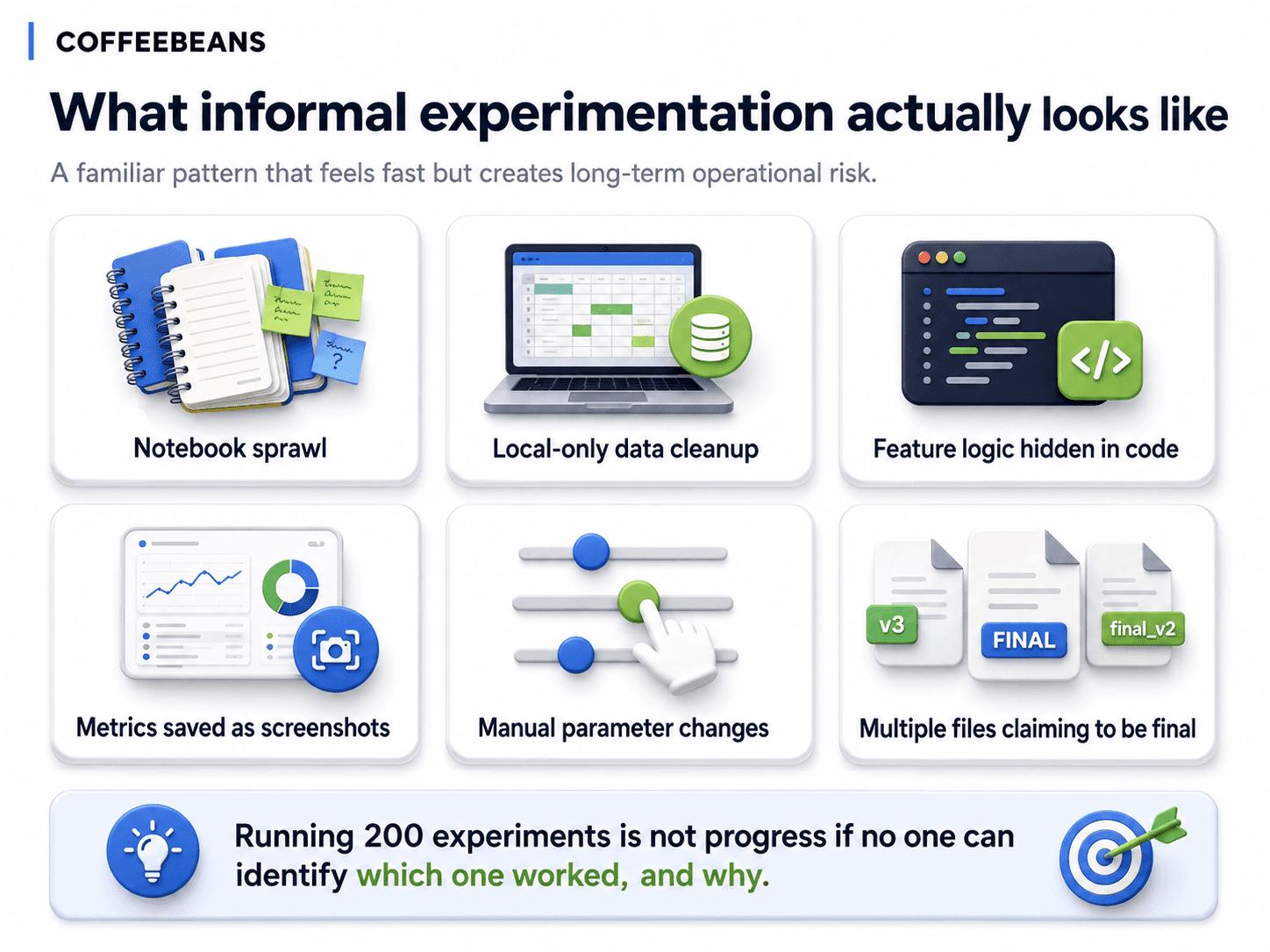
None of this is unusual. All of it is reasonable during early exploration. The risk arises the moment the team decides that one of these experiments has produced something worth deploying. At that point, the absence of structure becomes a governance problem.
Running 200 experiments is not progress if no one can identify which one worked, and why.
Why this becomes especially dangerous in mining and industrial AI
Models that influence operational decisions cannot rest on undocumented assumptions
In a working mining environment, an industrial AI model is rarely an isolated technical artefact. A predictive maintenance model for a SAG mill influences maintenance scheduling and spare parts planning. A crusher failure model affects production throughput decisions. A conveyor downtime model shapes shift planning. A fleet optimization model directs trucks and shovels across the pit. Each of these models supports decisions that have real operational, financial, and safety consequences.

When such a model cannot be reproduced, the consequences extend beyond inconvenience. The model cannot be audited. The assumptions behind it cannot be challenged. The performance baseline cannot be recomputed when the underlying conditions change. Retraining becomes high-risk because the team is unable to confirm that the new model was built on the same logical basis as the old one. And when something does go wrong in production, root cause analysis becomes guesswork.
For enterprise governance teams, the implication is direct. ML reproducibility enterprise is not a technical nicety. It is the prerequisite for treating industrial AI as a governed corporate asset rather than as a research output that happens to influence operations.
|
What a serious experiment tracking process should capture
The artefacts that turn an experiment into a reproducible result
Effective experiment tracking is not complicated, but it is deliberate. Each experiment should produce a structured record that captures, at minimum, the following:
Dataset version. The exact data extract used, with provenance back to source systems and a clear time range.
Feature set and feature definitions. The version of the feature pipeline that produced the inputs.
Label definition. How failure or the outcome of interest was defined and how labels were constructed.
Train, validation, and test split logic. Not just the percentages, but how the splits respected time, asset hierarchy, and operating conditions.
Algorithms and hyperparameters. The model type and the full configuration used during training.
Training code version. A specific code commit, not a description of what was approximately run.
Evaluation metrics. Against the agreed business cost function, not only generic statistical defaults.
Business outcome being measured. Tied to the operational decision the model is meant to support.
Assumptions and decisions. The data exclusions, imputation strategies, and methodological choices that shaped the result.
Owner and date. Accountability for the experiment and a timestamp for the work.

None of this is glamorous. All of it is what allows a model to move from an interesting result to a governed production candidate.
What MLflow and a model registry actually do
Plain-language framing for an executive audience
Tooling matters here, but the conceptual point matters more. MLflow experiment tracking is the most widely adopted open-source standard for logging machine learning experiments. In practical terms, it is the system that records every run the team executes — the parameters, the metrics, the artefacts, the code version, and the linked dataset — in a structured, queryable form. The team stops relying on notebooks and screenshots and starts relying on a controlled record.
A model registry is the layer above experiment tracking. It is where specific model versions are promoted from experimentation into a governed lifecycle. The registry records which model version is in development, which is in staging or pre-production validation, and which is approved for serving. It tracks ownership, approval status, deployment readiness, and audit history. It is, in practice, the control system that connects Stage 03 (model building) to Stage 04 (pre-production sign-off) and Stage 05 (deployment and serving).
A model registry is not a storage location. It is part of the control system for production AI.
Why accuracy alone does not tell leadership the right thing
Different experiments often optimise different outcomes
In an industrial AI programme, the most accurate model is not always the best model. This is particularly true in predictive maintenance, where the operational cost of false positives (unnecessary maintenance interventions) is rarely the same as the operational cost of false negatives (missed failures leading to unplanned downtime). One experiment may produce a model that maximises overall accuracy. Another may produce a model that improves recall on rare failure events at the expense of precision. A third may produce a model with lower headline accuracy but a longer lead time before failure, which the maintenance team values more highly.
What an informal comparison records | What a tracked experiment allows leadership to compare |
Which model had the highest accuracy? | Which model performed best against the operational cost function? |
A screenshot of evaluation metrics | Precision, recall, lead time, and false-alarm cost, side by side, across runs |
The data scientist's recollection of which experiment worked | A queryable record of every experiment, traceable to its inputs |
Which model can be reproduced and explained six months from now | |
Which model has the cleanest path to pre-production validation |
Without disciplined tracking, leadership cannot make this comparison. The team will report the model with the strongest visible result, and the decision to deploy will be made on incomplete information. With disciplined tracking, the same decision becomes evidence-based, auditable, and defensible to operations and governance stakeholders alike.
The leadership mistake we see repeatedly
Celebrating the number of experiments instead of the discipline behind them
The most common leadership mistake in Stage 03 is to treat the volume of experimental activity as a leading indicator of progress. The data science team reports that 250 experiments have been run. The slide shows momentum. The conversation moves on. The question that does not get asked is whether the experimentation process itself is controlled.
The better question, every time, is this: if this model works, can the team prove why it works and reproduce it again? If the answer is yes, the experimentation is progress. If the answer is no, the experimentation is exposure dressed up as productivity. In our experience, this distinction separates programmes that scale industrial AI from programmes that produce a stream of promising pilots and very few deployments.
|
How Stage 03 connects to the rest of the value chain
Reproducibility is what makes downstream stages possible
Stage 03 of the CoffeeBeans AI Productionization Value Chain is not complete when a model performs well in a notebook. It is complete when the experiment that produced the model is reproducible, the model is registered, and the candidate is ready for pre-production validation. Without that completion, the dependency chain breaks at every subsequent stage.
Stage 04, Pre-Production Sign-off, depends on the ability to validate the candidate model against the exact training conditions that produced it. Shadow mode testing, business metric validation, and edge case analysis all require a reproducible experiment to anchor the validation to. Without it, the team is validating an artefact whose origin cannot be confirmed.
Stage 05, Model Deployment and Serving, requires a model registry artefact that is versioned, owned, and approved. A model deployed without these properties cannot be rolled back cleanly, replaced safely, or audited credibly. It is in production. It is not under control.
Stage 06, Model Health and Performance, requires the original evaluation baseline to monitor performance drift against. When the model degrades, the team needs to know whether the cause is data drift, feature drift, or natural concept drift, and to retrain on a comparable basis. None of this is possible if the original experiment cannot be reproduced.
How CoffeeBeans helps
Bringing experiment governance to industrial AI programmes
CoffeeBeans works with mining and industrial organisations to bring ML reproducibility enterprise discipline into Stage 03 of the AI productionisation chain. Our engagements typically establish MLflow experiment tracking as the operational standard for model development, define the experiment record structure that the organisation will hold its data science teams to, and build the model registry workflow that connects experimentation to validation and deployment.

From there, we put model registry best practices in place as a working system, not as a policy document. Approval gates, ownership, versioning, environment promotion (development to staging to production), and rollback procedures are configured to match the operational reality of the organisation. The objective is not to slow the data science team. The objective is to make sure that every experiment that produces a strong result is automatically a candidate that can be validated in Stage 04, deployed in Stage 05, and monitored in Stage 06 without rework.
When industrial AI programmes generate many experiments and few production models, the binding constraint is rarely the model itself. It is the absence of the experimentation discipline that makes a model trustworthy. CoffeeBeans builds that discipline into the work.
If your best model works, can your team prove why it works?
If your data science team is producing many experiments and very few deployed models, the gap is rarely in the algorithms. It is in the discipline that connects experimentation to production. CoffeeBeans can assess your current experimentation practice, establish MLflow experiment tracking and model registry best practices, and build the governance layer that ML reproducibility enterprise requires to scale industrial AI. Talk to our Enterprise AI practice about Stage 03 discipline in your operation.
Like What You’re Reading?
Subscribe to our newsletter to get the latest strategies, trends, and expert perspectives.
Similar Reads



Links
Subscribe
Newsletter
Sign up to learn about AI in the business world.
© 2026 CoffeeBeans. All Rights Reserved.