The historian is not your data foundation
A process historian stores what happened in your plant. An industrial AI data foundation explains why it happened and makes data usable in production AI. Here is the difference.

6
min read

Process historians are built to store operational time-series data. They are not built to make that data AI-ready. Here is what the gap actually looks like.
Every leadership conversation we have with mining and industrial organisations about AI readiness eventually arrives at the same moment. Someone references the historian. "We have PI. We have all the data." It is said with the confidence of someone who knows what they are talking about. And they are not wrong. Most large mining and processing operations have been running OSIsoft or AVEVA PI for a decade or more. Tens of thousands of tags, logged continuously, available for query.
And yet the AI initiatives stall. The predictive maintenance model that performed well in the notebook does not reach the control room. The anomaly detection system that impressed in the proof of concept cannot be sustained in production. The data science team keeps requesting information that the historian cannot supply.

The root cause is a conflation of two fundamentally different capabilities: data storage and data readiness for AI. A process historian excels at the first. It was never designed for the second. That distinction, seemingly technical, is the reason most industrial AI programmes plateau between pilot and production.
Data stored in a historian is not the same as data prepared for AI.
What historians do well
Process historians were built to solve a specific and important problem. Industrial operations generate enormous volumes of time-series data from sensors, instruments, and control systems. That data needs to be captured reliably, stored efficiently, and made available for operational monitoring and reporting. Historians do this exceptionally well.
AVEVA PI, the most widely deployed historian in heavy industry, can ingest data from thousands of OPC-connected instruments simultaneously, compress and store readings with high fidelity, and serve those readings to dashboards, reports, and control system displays in near-real time. In a mining environment, this means that vibration from a SAG mill bearing, pressure across a pump seal, temperature in a flotation cell, and belt load on a conveyor can all be logged at second-level or sub-second resolution, continuously, across years of operation.
That is genuinely valuable. The operational history captured in a well-maintained historian is one of the most important assets a mining organisation has. The problem is not that historians are inadequate. The problem is what happens when teams assume that the historian is also the AI data foundation.
A historian can tell you what happened in the plant. A data foundation helps AI understand why it happened, whether the data can be trusted, and how it can be used reliably in production.
Where the misconception begins
The confusion is understandable. Historians have been the authoritative system of record for operational data in mining and process industries for decades. They sit at the centre of the operational technology stack. When a CIO or CDO is asked whether the organisation has the data to pursue AI, pointing to the historian is both instinctive and accurate.
What the historian does not surface from the outside is what it was never built to provide for AI. It stores what was measured. It does not store why it matters. It captures tag values. It does not capture operating context, asset state, failure history, maintenance records, ore type, or shift conditions. It records the signal. It does not record the meaning behind it.
For operational monitoring and process dashboards, this is entirely sufficient. Experienced engineers carry that context. They know which tag belongs to which piece of equipment, what the normal operating envelope looks like, and how to interpret deviations in the context of that shift, that material, that maintenance cycle.
An AI model has no such institutional memory. It learns only from what exists in the data. A historian's output, without systematic enrichment and preparation, is missing the majority of what a model requires to make reliable predictions in production.
|
What historian data is missing for AI
Consider a concrete example from a mining processing plant. A vibration sensor on a SAG mill bearing logs readings every second. That data exists in the historian. But for an AI model predicting bearing failure, the historian reading alone answers only one of the questions the model needs answered:
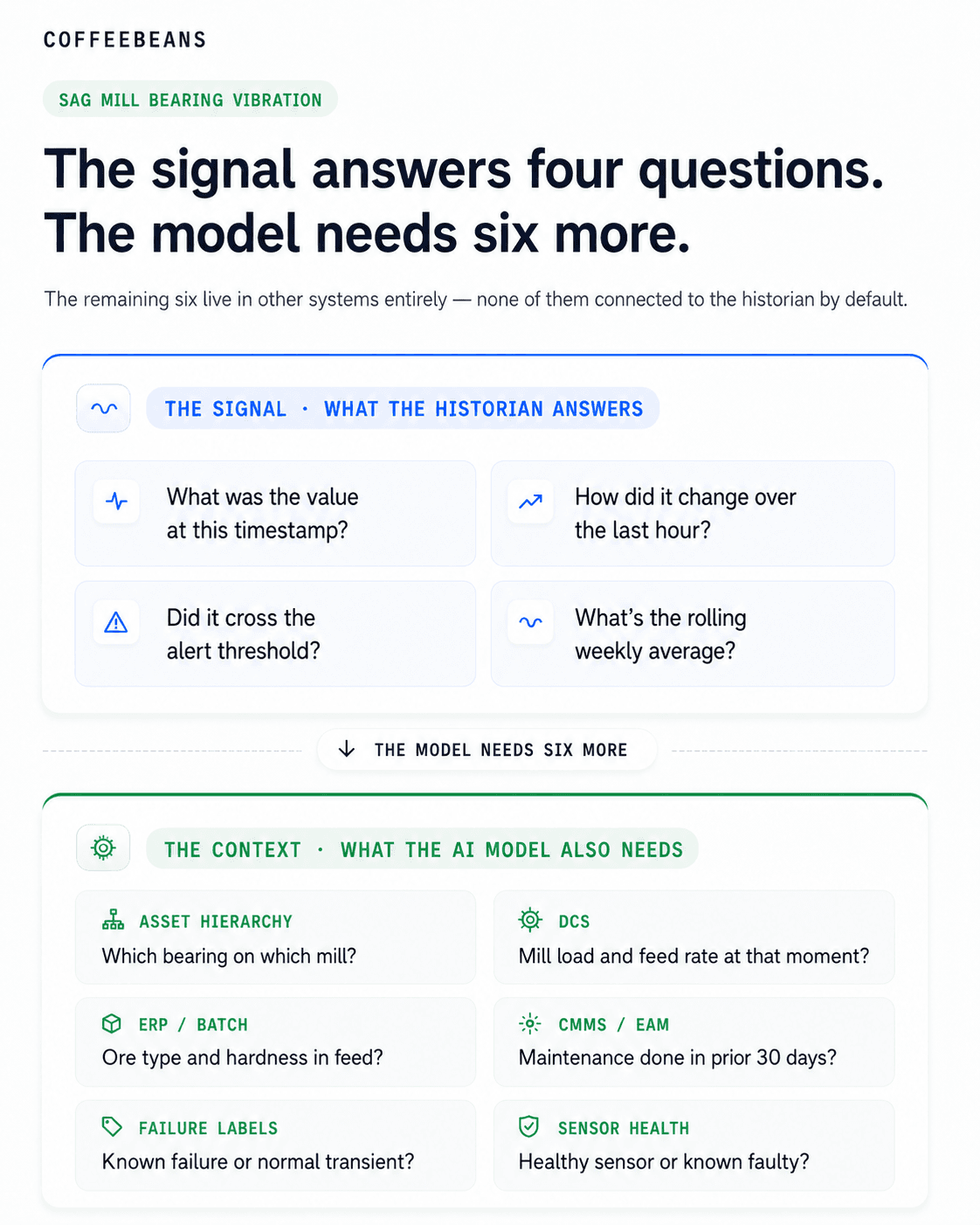
What the historian answers | What the AI model also needs |
What was the vibration reading at this timestamp? | Which bearing on which mill generated this reading? |
How did the reading change over the last hour? | What was the mill load and feed rate at that moment? |
Did the reading exceed the alert threshold? | What ore type was being processed and at what hardness? |
When did the reading return to normal? | Was there a maintenance event on this bearing in the prior 30 days? |
What was the average reading over the past week? | Was this a known failure or a normal transient excursion? |
Is this tag from a healthy sensor or one with known calibration issues? | |
Can this logic be run again tomorrow on the production pipeline? |
The answers to the historian's column exist in the historian. The answers to the AI model's column exist in other systems: the CMMS or EAM for maintenance history, the ERP for material type and batch records, the DCS for operating mode and load data, the asset management system for equipment hierarchy and sensor health. None of those systems is connected to the historian by default. None of that data is in a form that an ML pipeline can consume directly.
This is the gap. Not the volume of data. The context, governance, and integration that turns stored readings into model-ready features.
KEY POINT: The gap is not storage. The gap is context, governance, and production readiness. |
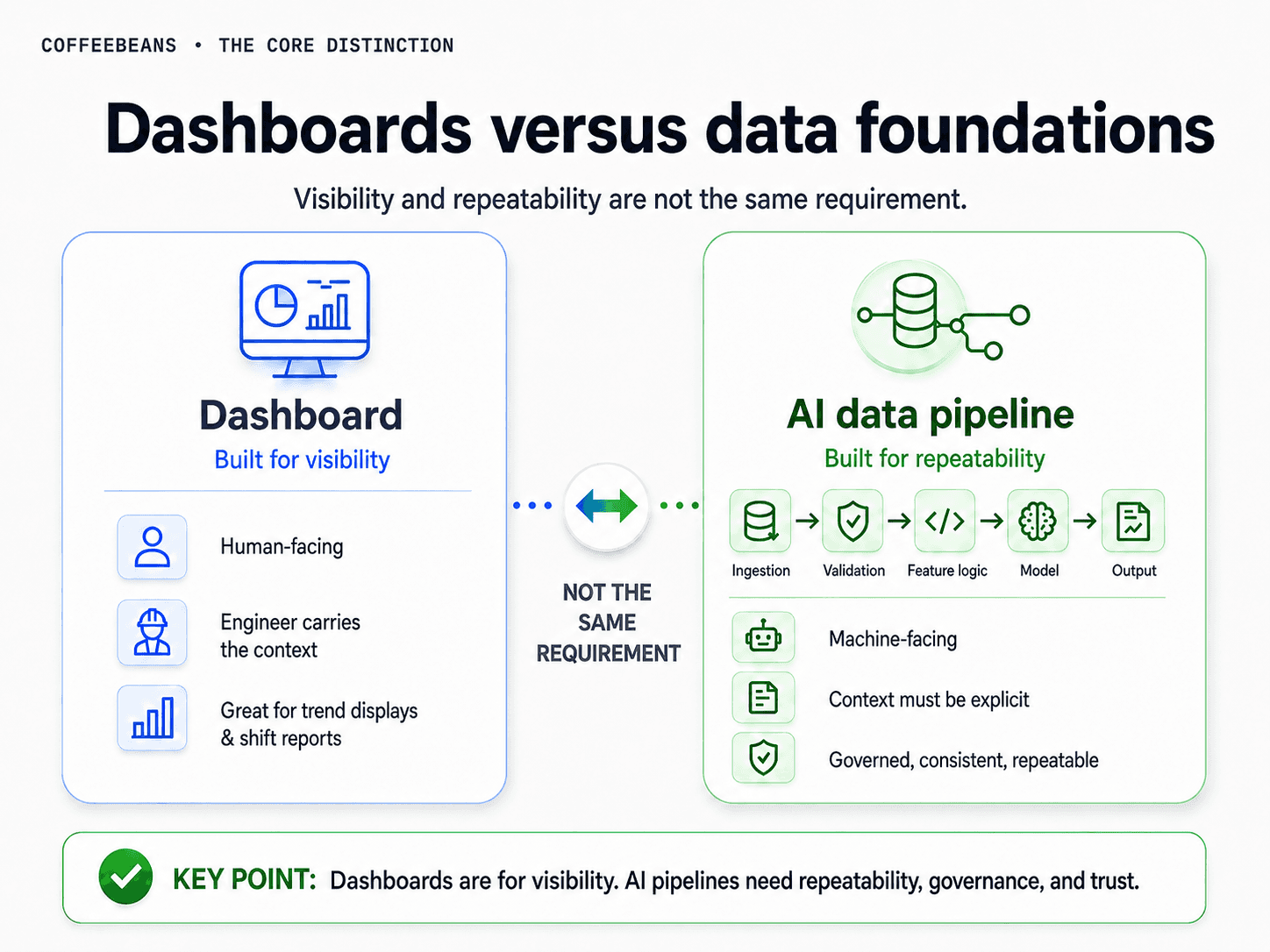
Dashboards versus data foundations
Historians are also the data source for most operational dashboards. Trend displays, process overview screens, KPI panels, and shift reports all pull from historian data. This creates another version of the same misconception: because the data drives excellent dashboards, it must also be ready for AI.
Dashboards and AI pipelines have fundamentally different requirements. A dashboard is built for a human expert who already has context. The chart shows a trend, and the process engineer interprets it against their experience of that equipment, that ore type, that shift pattern. The dashboard does not need to explain what it is showing. The engineer already knows.
An AI pipeline requires that context to be explicit in the data. The model has no prior experience. It cannot ask the shift supervisor what ore was being fed at 2am on a Tuesday in March. It can only learn from what is recorded. And if the context is not recorded and connected to the signal, the model cannot learn what matters.
|
What a real industrial AI data foundation looks like
An industrial AI data foundation is not a replacement for the historian. The historian remains the source of time-series operational data. What the foundation adds is the layer that makes historian data, and every other data source across the operation, usable for AI in production.
A real foundation includes all of the following:
Connected OT and IT data: Historian time-series joined with maintenance records, asset hierarchies, operational schedules, and process conditions from ERP, CMMS, and DCS systems
Trusted source definitions: Clear documentation of which tags are reliable, which instruments have known issues, and which data sources are authoritative for each use case
Asset hierarchy and metadata: Equipment context that maps each tag to a specific asset, location, operating unit, and criticality level
Failure labels and operating modes: Structured records of known failure events, maintenance interventions, and operational state changes that give models something to learn against
Governed data access: Defined ownership of each data source, access controls, and audit trails that establish who used which data and when
Feature-ready pipelines: Repeatable transformation logic that converts raw readings into engineered features consistently, in both training and production environments
Data quality and freshness monitoring: Automated checks that detect gaps, outliers, sensor faults, and stale readings before they reach a model
Traceability from source to model: The ability to follow any model input back to its original source, transformation logic, and quality check
The historian can feed into this foundation. In fact, it is typically the most important data source within it. But a historian alone is not a foundation. It is one layer of the infrastructure that a foundation needs to connect, govern, and prepare.
|
Why this matters for every stage of AI productionisation
At CoffeeBeans, we work within a six-stage AI Productionization Value Chain. Stage 01, Data Readiness and Trust, is where the industrial AI data foundation is established. Every stage that follows depends on it.
Stage 02, Signal Creation and Data Prep, requires stable, trusted data sources that can be transformed into features consistently. If the only source is the historian and maintenance context is missing, the features will be incomplete. The model will train on a partial picture of reality.
Stage 03, Model Building and Experimentation, requires reproducible training datasets. If the data preparation logic is not codified in a governed pipeline, each experiment will be built on a slightly different data extract. Results will be difficult to compare and impossible to reproduce.
Stage 04, Pre-production sign-off and Stage 05, Model Deployment and Serving, requires that production pipelines replicate training conditions in real time. If the training pipeline pulled from the historian and the production pipeline does the same without the same feature engineering and quality checks, the model will serve on different data than it was trained on. That is one of the most common causes of production AI failure.
Stage 06, Model Health and Performance, requires ongoing monitoring of input data quality. Without a governed data foundation, there is no baseline to monitor against. Changes in historian tag coverage, sensor faults, or schema updates will silently degrade model performance with no detection mechanism in place.
In a recent engagement with a large mining operation running heavy equipment fleets across challenging terrain, CoffeeBeans encountered exactly this problem at scale. Each piece of equipment was generating thousands of sensor parameters per second. The data volume was not the challenge. The challenge was that sensor streams from different manufacturers used different formats, tag conventions, and data contracts. There was no shared schema, no common metadata, and no connection to the maintenance records or operational history that a predictive model needed. A model trained on raw sensor readings alone would have learned from noise. The work began not with algorithm selection, but with building the data foundation: unified ingestion pipelines, cross-system integration of sensor and maintenance data, and a feature engineering layer that gave the model the operational context it required. Only then did model building begin.
In our experience, the operations that move AI from pilot to production most reliably are those that invest in the data foundation before the model. The historian is where that foundation starts. It is not where it ends.
How CoffeeBeans helps
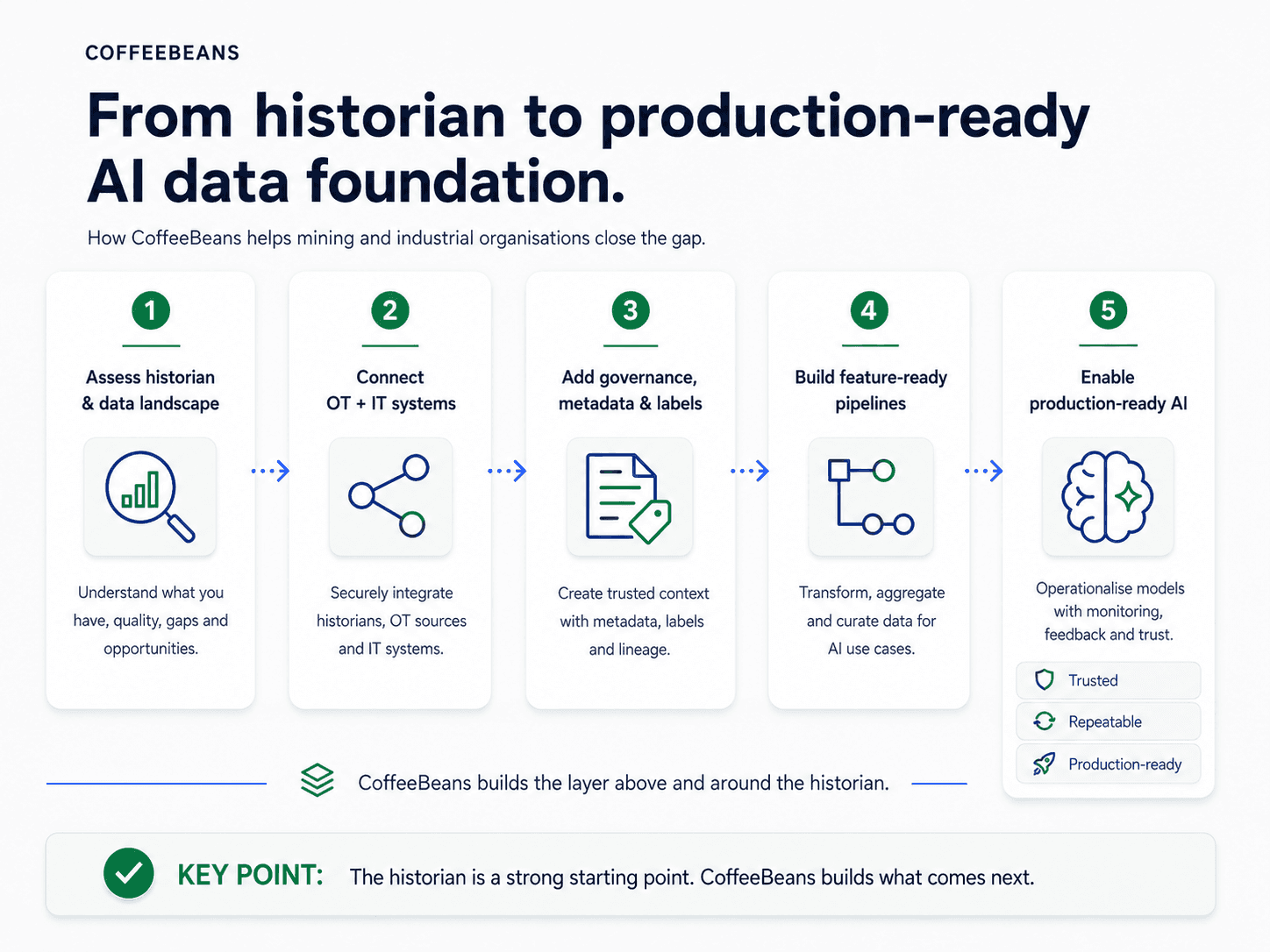
CoffeeBeans works with mining and industrial organisations to build the industrial AI data foundation that sits above and around the historian. This is not a historian replacement project. It is an integration and governance layer that connects historian data with the maintenance, operational, and enterprise data that AI models need.
Our SCADA data AI readiness work typically begins with understanding exactly what the historian holds: which tags, at what resolution, with what coverage, and with what gaps. From there, we identify the other systems that carry the context the historian does not, and we design the pipelines that bring those sources together in a governed, production-ready architecture.
The goal is to make process historian machine learning practical. Not as a one-time data extract for a proof of concept. As a production system that runs reliably, monitors its own data quality, and supports the full AI productionisation chain from signal creation through to model health monitoring.
The historian is a strong starting point. CoffeeBeans builds what comes next.
Is your historian the beginning of your AI data foundation, or the whole of it?
If your operation holds rich historian data but AI initiatives that are not reaching production, the gap is almost always in what the historian does not carry: asset context, maintenance history, failure labels, and governed integration across the full operational data stack. CoffeeBeans can assess where your industrial AI data foundation stands, identify the readiness gaps that are holding back production AI, and build the infrastructure to close them. Talk to our Enterprise AI practice about SCADA data AI readiness for your operation.
Like What You’re Reading?
Subscribe to our newsletter to get the latest strategies, trends, and expert perspectives.
Similar Reads



Links
Subscribe
Newsletter
Sign up to learn about AI in the business world.
© 2026 CoffeeBeans. All Rights Reserved.