Raw sensor data is not a feature. This is what stands between them.
Raw sensor data is not a feature. Effective feature engineering in mining AI turns SCADA readings into signals models can learn from. Here is what that work requires.

6
min read

Over the last two articles in this series, we have argued that mining organisations rarely have a data shortage. They have a data readiness problem, and they have a habit of mistaking a process historian for a data foundation. Both issues belong to Stage 01 of the AI Productionization Value Chain. This week, the conversation shifts to the next stage and to a question that, in our experience, is asked far too late in most industrial AI programmes.
What signal are we actually asking the model to learn from?
It sounds straightforward. It is not. A SCADA tag is not a signal. A vibration reading is not a signal. A truck cycle time is not a signal. Each of these is a data point. A signal is something quite different: a structured representation of operational behaviour over time, enriched with context, aligned to events, and engineered to be learned from. The work of building that representation is what Stage 02 of the value chain is for. And it almost always takes longer than the modelling that follows it.
|
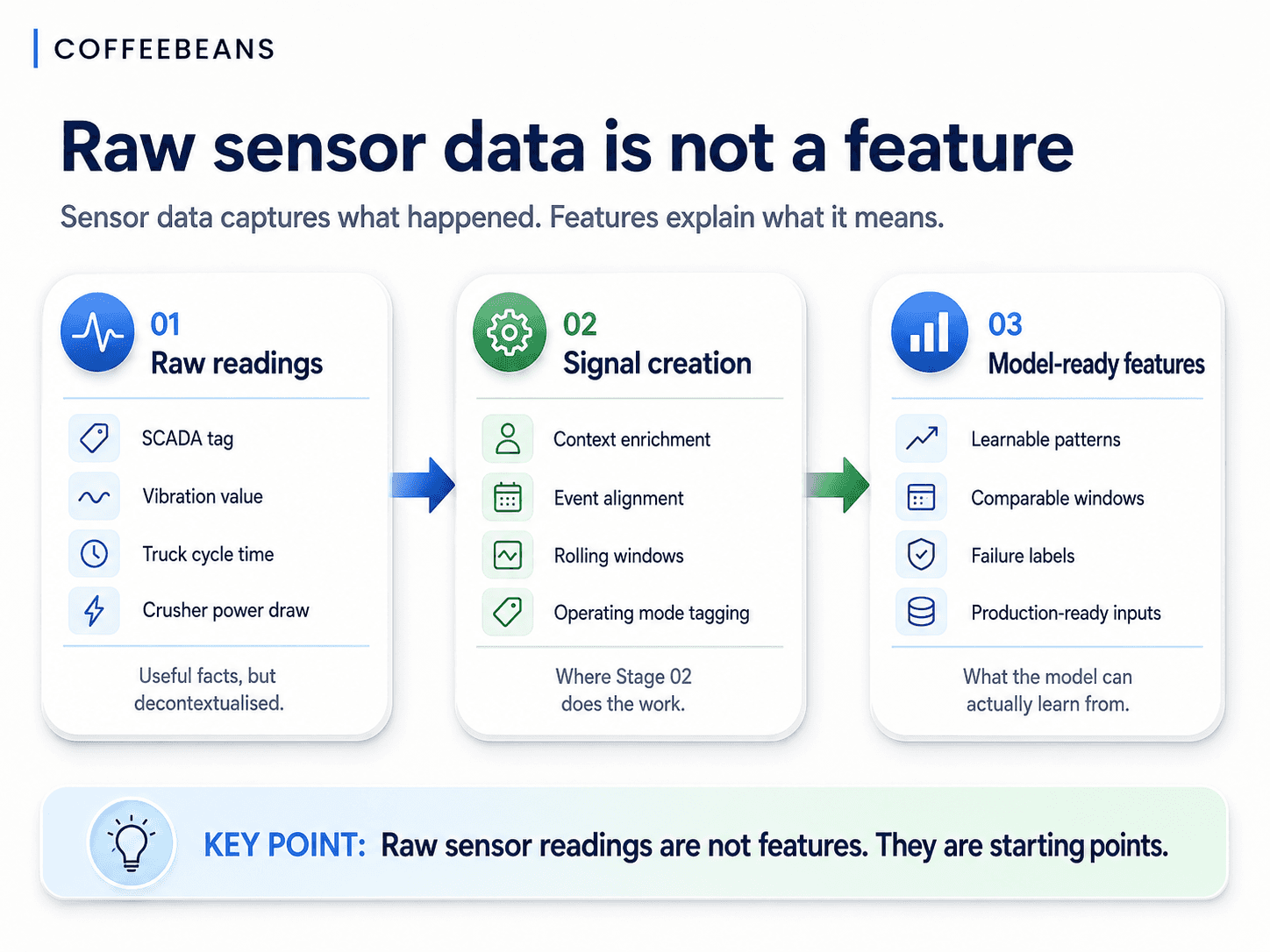
What raw sensor data actually is in a mining operation
A high-volume stream of decontextualised measurements
A modern mine or processing plant generates an enormous and continuous stream of measurements: vibration on a SAG mill bearing, temperature in a flotation cell, pressure across a pump seal, power draw on a crusher, belt load on a conveyor, fuel consumption and idle time on a haul truck, throughput at the primary crusher, flow rates through reagent dosing systems. These readings are valuable. They are also, on their own, almost entirely unusable for machine learning.
A single vibration value at a single timestamp tells a model very little. A power draw reading at 14:32 means nothing without knowing what the asset was doing at 14:31, what it was doing at 14:00, what ore was being processed, whether maintenance had recently been performed, and whether the surrounding pattern resembles anything the model has seen before. The reading is a fact. The signal is an interpretation.
A reading tells you what was measured. A signal tells you what was happening — and that is what a model needs in order to learn anything useful.
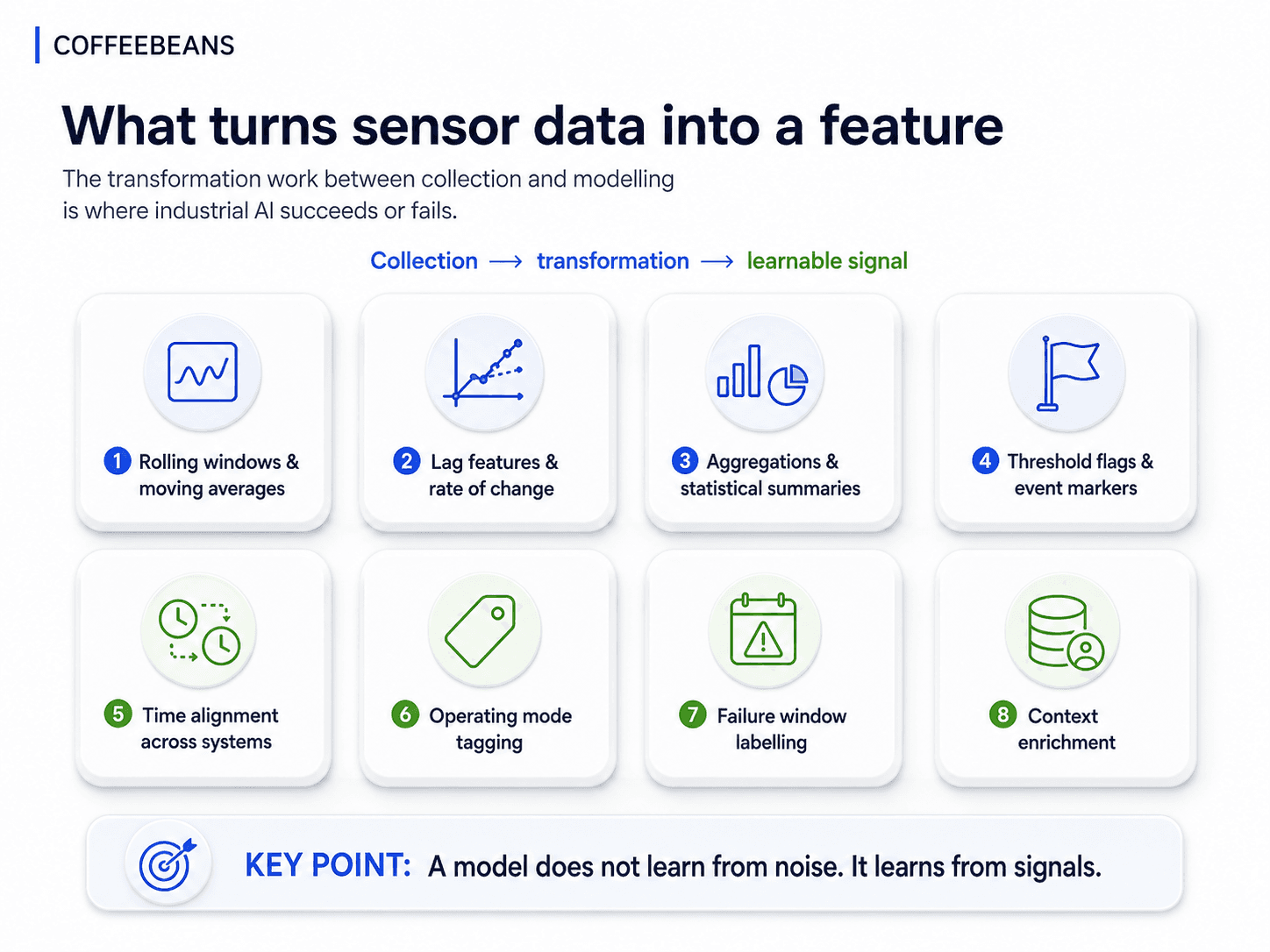
What turns sensor data into a feature
The transformations that sit between collection and modelling
Stage 02 of the CoffeeBeans AI Productionization framework — Signal Creation and Data Prep — is the layer where raw operational data is converted into engineered features. The work is not glamorous. It is also where most of the real industrial AI value is created.
The transformations involved typically include:
Rolling windows and moving averages. A single reading is rarely meaningful. A 5-minute, 15-minute, or 60-minute window of readings reveals trend, stability, and excursion.
Lag features and rate of change. How the signal evolved over the last interval is often more predictive than its current value.
Aggregations and statistical summaries. Means, standard deviations, peaks, and counts within defined intervals turn raw streams into shape descriptors a model can learn from.
Threshold flags and event markers. Encoding when a parameter crossed an operational limit, or when a maintenance event occurred, gives the model anchor points to reason against.
Time alignment across systems. Sensor data, fleet events, and maintenance records are recorded on different clocks. Aligning them to a common timeline is a prerequisite for any meaningful feature.
Operating mode tagging. Whether the asset was under load, in standby, in startup, or in a known abnormal condition fundamentally changes what the signal means.
Failure window labelling. Knowing that a 72-hour window preceded a confirmed failure event is what turns a stream of readings into a supervised learning dataset.
Context enrichment. Linking the signal to asset hierarchy, ore type, shift, or batch ID converts an isolated measurement into something the model can generalise from.
Each of these transformations is technical. Together, they are the difference between data that exists and data a model can actually learn from. In practice, signal creation often consumes 60 to 70 percent of the work required to deliver a production-grade industrial AI model. The modelling itself, in our experience, is rarely the bottleneck.
|
What this looks like in practice
A vibration reading is not a prediction
Consider a practical example. An AI model is being built to predict bearing failure on a SAG mill. The historian holds high-frequency vibration data going back several years. The data is available. The data foundation, built during Stage 01, has connected that vibration data to maintenance records, asset hierarchy, and process conditions. The Stage 01 work is done. The Stage 02 work is just beginning.
What a raw vibration reading answers | What a model-ready feature must answer |
What was the vibration value at this timestamp? | Is this value normal for this asset under this operating condition? |
Was the value above or below the operational threshold? | Is the value rising, falling, or stable over the last 15 minutes? |
What was the reading recorded in the previous interval? | Has this pattern appeared before a confirmed failure? |
What is the average reading for the last shift? | Was the asset under load, in startup, or in standby? |
What is the variance across the last hour? | Was maintenance recently performed on this bearing? |
Is this signal aligned with ore type, throughput, and shift context? | |
Can the same feature be produced reliably in the production serving pipeline? |
The right-hand column is the feature space. It is where the model learns. None of it exists in the historian. All of it has to be engineered, governed, and made reproducible in production. This is what Stage 02 delivers.
|
Why signal creation takes longer than modelling
Domain understanding, not algorithm selection, is the bottleneck
There is a recurring pattern in industrial AI programmes that I have seen across multiple operations. The model is trained quickly. The proof of concept performs well. The team is ready to deploy. And then the question lands: can this feature be reproduced reliably in the production pipeline, on live data, every minute, for the next two years? The answer, far too often, is no.

This is because signal creation is not primarily an algorithmic exercise. It is a domain and engineering exercise. It requires understanding what 'under load' actually means for a specific asset class. It requires knowing how maintenance teams record events, what the typical lag is between a failure and its log entry, and how shift handovers affect operational data. It requires building pipelines that produce identical feature outputs in both training and serving environments, every time. None of that work is visible in a notebook. All of it determines whether a model survives in production.
Industry research consistently reflects this. McKinsey's manufacturing AI research, Deloitte's industrial transformation studies, and Gartner's MLOps guidance all converge on the same observation: the organisations that scale AI successfully are those that invest in feature engineering and data pipeline rigour before they invest in modelling sophistication. The algorithm is not the differentiator. The signal is.
If the signal is poorly defined, the algorithm will only automate confusion at a faster rate.
The leadership mistake we see repeatedly
Choosing the model before defining the signal
The most common mistake in industrial AI programmes is not technical. It is sequencing. Leadership teams arrive at AI roadmap discussions with a question already formed: which model should we use for predictive maintenance? Should we go with XGBoost, deep learning, or a time-series transformer? The question is reasonable. It is also premature.
The better question, every time, is this: what signal are we asking the model to learn from? Until that question has been answered with operational specificity — what variables, what windows, what context, what labels, what production pipeline — the choice of algorithm is largely irrelevant. The same model on a poorly defined signal will fail. A simpler model on a well-defined signal will outperform it.

For leadership teams, the practical implication is straightforward. When evaluating an industrial AI investment, the right diagnostic is not whether the data science team has selected a sophisticated algorithm. It is whether the team has done the upstream work to define and engineer the signals that algorithm will operate on. That work is what determines whether the programme reaches production or stalls at proof of concept.
|
How Stage 02 supports the rest of the value chain
Feature engineering as the connective tissue of production AI
In the CoffeeBeans AI Productionization framework, Stage 02 sits between Stage 01 (Data Readiness and Trust) and Stage 03 (Model Building and Experimentation). It is the layer that takes a trusted data foundation and converts it into the model-ready feature space that every later stage depends on.
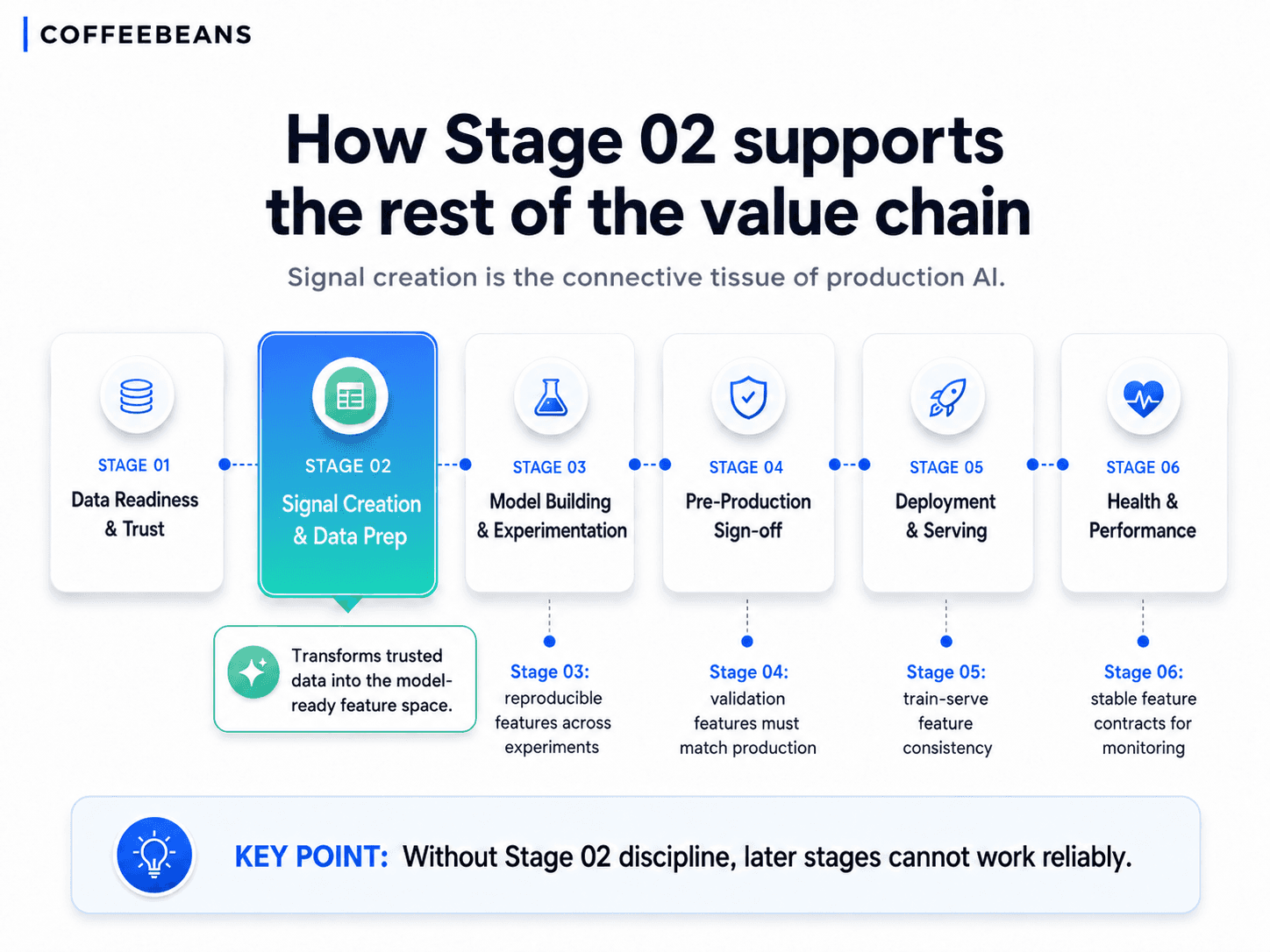
Stage 03 requires features that are reproducible across experiments. Without Stage 02 discipline, every data scientist runs experiments on a slightly different feature definition, and results cannot be compared.
Stage 04, Pre-Production Sign-off, requires the production feature pipeline to be ready for shadow mode testing. The features generated in the validation environment must match exactly what the production pipeline will deliver. If Stage 02 has not produced governed, repeatable feature logic, Stage 04 cannot do its job.
Stage 05, Model Deployment and Serving, depends entirely on train-serve feature consistency. The single most common cause of production AI failure in industrial environments is a serving pipeline that produces features differently from the training pipeline. That is a Stage 02 failure, surfacing late.
Stage 06, Model Health and Performance, requires input feature monitoring to detect drift. Without a defined feature contract from Stage 02, there is nothing stable to monitor against, and degradation goes undetected until it affects operations.
How CoffeeBeans helps
From sensor reading to production-grade feature pipeline
CoffeeBeans works with mining and industrial organisations to build the signal creation ML pipelines that turn historian and SCADA data into model-ready features at production scale. Our feature engineering for mining AI work is grounded in operational reality. Before any transformation logic is written, our teams work with maintenance, operations, and process engineers to understand what 'under load' means for each asset class, how failure events are actually recorded, and what context needs to be enriched into the data.
From that foundation, we design and build the feature pipelines themselves: rolling-window logic, lag features, event alignment, operating mode tagging, and failure window labelling — engineered into a governed feature store that produces identical outputs in training and production. The objective is not a one-time data preparation. The objective is industrial sensor data machine learning infrastructure that runs reliably for years, supports multiple downstream models, and gives the operations team confidence in what the AI is learning from.
In our experience, when mining AI programmes stall between pilot and production, the issue is almost never in the algorithm. It is in the signal. CoffeeBeans builds the layer that closes that gap.
Are you building models, or are you defining signals?
If your industrial AI programme is producing strong proofs of concept that struggle to reach production, the gap is almost certainly in Stage 02. CoffeeBeans can help your team define the signals your models should be learning from, build the signal creation ML pipeline to produce them reliably in training and serving, and put the feature governance in place that production AI requires. Talk to our Enterprise AI practice about feature engineering for mining AI in your operation.
Like What You’re Reading?
Subscribe to our newsletter to get the latest strategies, trends, and expert perspectives.
Similar Reads



Links
Subscribe
Newsletter
Sign up to learn about AI in the business world.
© 2026 CoffeeBeans. All Rights Reserved.